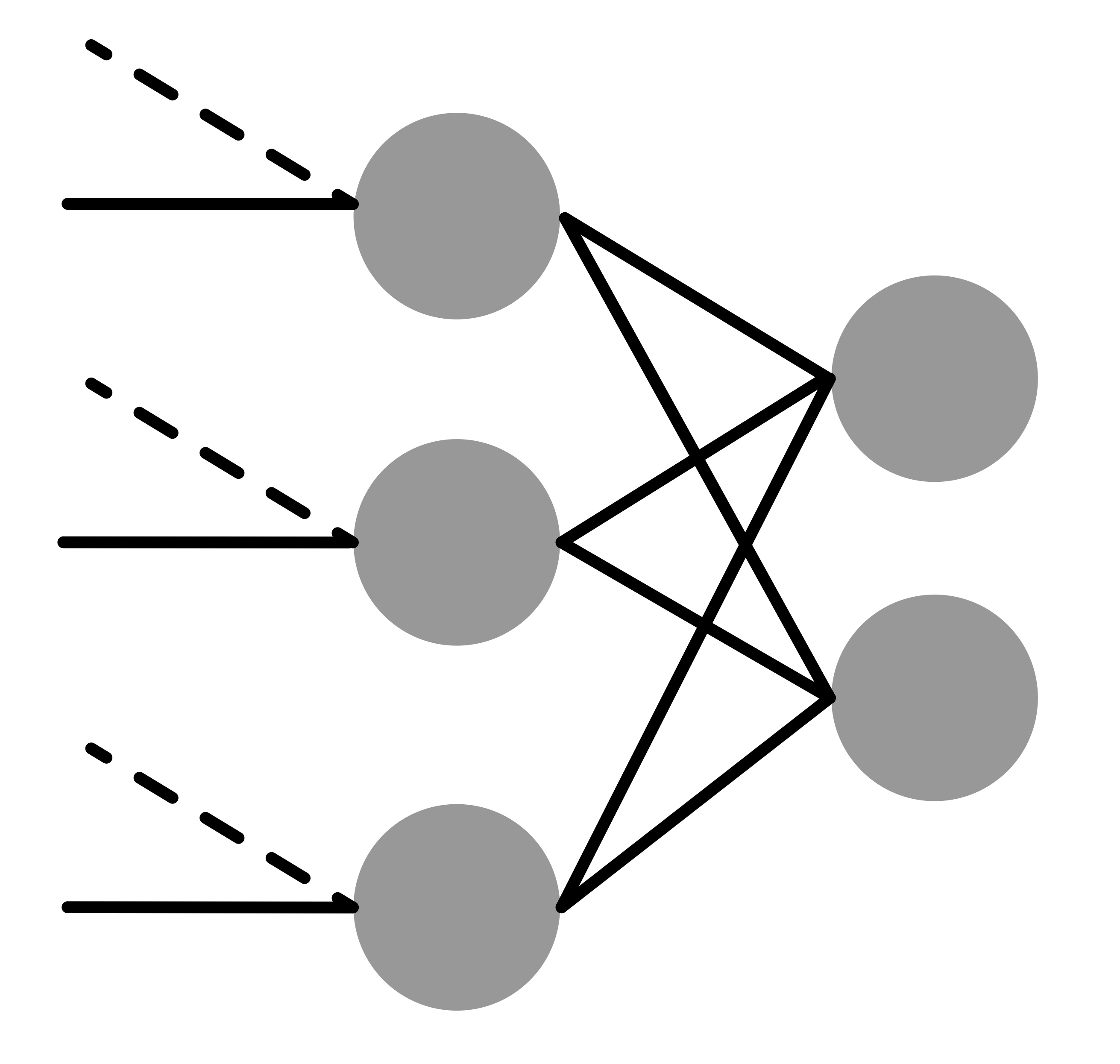
I’m interested in adding a new input to every node in a layer for a defined architecture. I made a quick graphic in a simple network. The nodes and solid lines are the existing architecture, and I want to add a new input (dashed lines) to each node in a layer. I only want my new input to map a single connection to the corresponding node in the layer.
Would you like to add these values to the output activations of another layer?
If so, just add this tensor to the output of a specific layer in your forward method:
def forward(self, x, additional_x):
x = F.relu(self.fc1(x))
x = x + additional_x
x = F.relu(self.fc2(x))
...
return x
I might have misunderstood your question. x1, x2, … would be the inputs to your model which are just summed.
Would you like to pass these inputs separately to the same layer?
x = self.fc(x) will store the output activations in x. You can pass it to a new layer just by calling self.fc2(x). Could you explain the first image a bit, as I’m still unsure about your use case?
where I have three types of data that contribute to every node, but the inputs are specific to that node. How would I implement the input and output layers?
I tried writing an autoencoder that does what I’m looking for. Does it match up with the picture I posted? Also, is there any way to parallelize the for loops?
class Model(nn.Module):
def __init__(self, layer_size):
super(Model, self).__init__()
self.layer_size = layer_size
self.relu = nn.ReLU()
self.contract = nn.Linear(3, 1)
self.fc1 = nn.Linear(layer_size, 100)
self.fc2 = nn.Linear(100, layer_size)
self.expand = nn.Linear(1, 3)
def forward(self, x):
# x.shape (batch_size, layer_size, 3)
outs = []
for i in range(self.layer_size):
outs.append(self.relu(self.contract(x[:, i, :])))
x = torch.cat(outs, dim=1)
x = self.relu(self.fc1(x))
x = self.relu(self.fc2(x))
outs = []
for i in range(self.layer_size):
outs.append(self.relu(self.expand(x[:, [i]])))
x = torch.stack(outs, dim=1)
return x
You don’t need to slice and concatenate x, as nn.Linear layers will take an input of [batch_size, *, in_features] and apply the linear layer on all additional dimensions specified as *.
However, I’m still unsure about your picture.
The dots represent the activations, while the lines should represent the weight matrices (or the linear layers in general).
What would the first and last lines represent?
Thanks for your patience. I think it will be easier to explain my use case if I give an example.
Let’s say I have manufacturing data from 100 factories. All of these factories have 50 machines. For each machine, I have 3 features (time in use, machine type, number of times serviced). I can formulate my input tensor with the shape (100 factories, 50 machines, 3 features). I want the first layer of my network to have 50 nodes, each corresponding to one of the 50 machines. Each node in the first layer will take the 3 input features associated with one machine. So, each of the 3 features will have its own weight, which contributes to the activation of the “machine” node. This network can now be trained on an output label corresponding to each factory or as an autoencoder.
Now let’s say I have a pretrained model with this architecture, but I have a 4th feature that I want to incorporate. How can I add a 4th input to my “machine” layer?
I hope this is clear! Please tell me if anything needs clarification.