Hi,
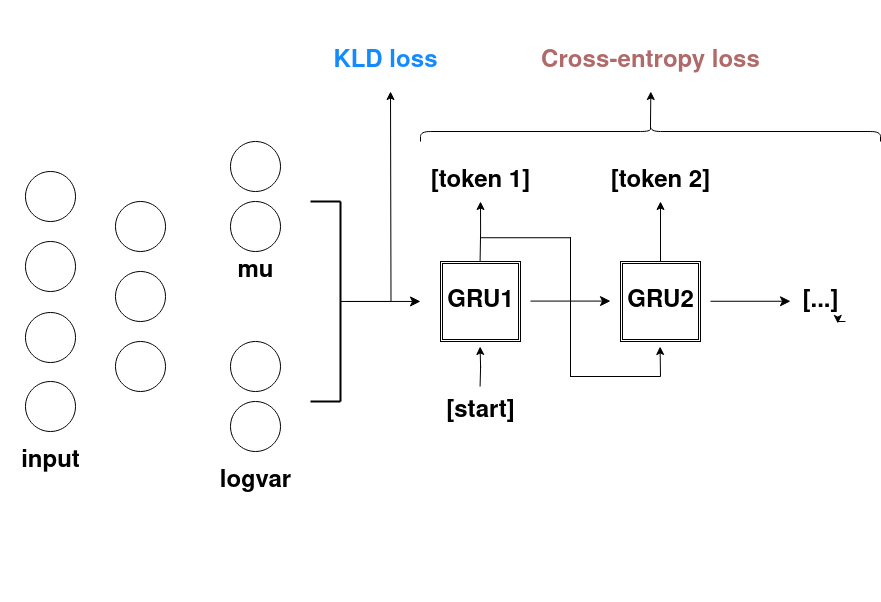
My model is an autoencoder-like neural net which takes a sparse bit vector of fixed len as an input and passes it through a VAE encoder. Reparametrization trick is used to sample the latent space and the latent vector is passed to GRU, which decodes it into a sequence of letters (tokens). The model is supposed to ‘describe’ the input bit vector with a sequence of tokens.
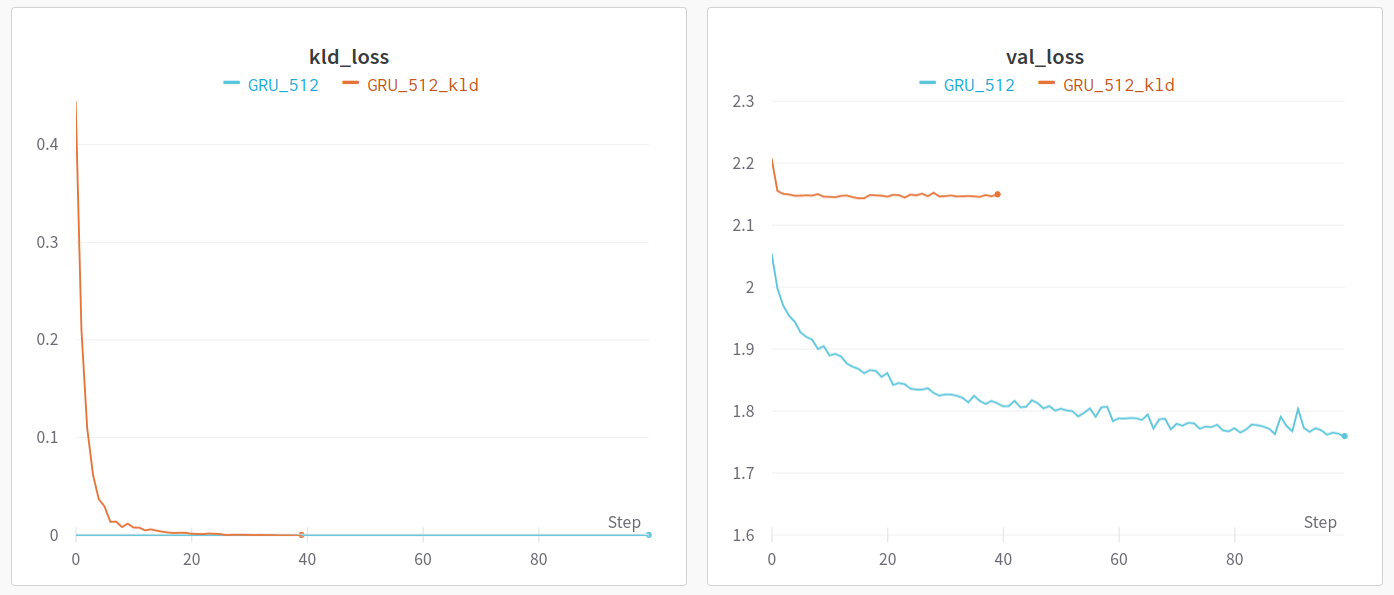
Now, the issue is as follows: when I trained the neural net, caring only about Cross-entropy loss (losss calculated on the output sequence) the model learns quickly and gets pretty good at the task (see graphs in my comment below). However, I need the encoder latent space to have normal distribution in order to sample from it and use the whole network as a generative model.
If I include KLD loss in the backward pass, the optimizer seems to completely ingore the task of minimizing the cross-entropy and drives the KLD loss to almost zero. This happens even if KLD loss is multiplied by a very low weight prior to .backward()
Thanks for all ideas and feedback.
# Training loop
optimizer = torch.optim.Adam(model.parameters(), lr=learn_rate)
for epoch in epochs_range:
model.train()
epoch_loss = 0
kld_loss = 0
for X, y in train_loader:
X = X.to(device)
y = y.to(device)
optimizer.zero_grad()
output, kld_loss = model(X, y, teacher_forcing=True, reinforcement=False)
kld_loss = kld_loss * kld_weight
loss = criterion(y, output)
if kld_backward:
(loss + kld_loss).backward()
else:
loss.backward()
optimizer.step()
# KLD loss calculation inside model.encoder instance
def kld_loss(mu, logvar):
KLD = -0.5 * torch.sum(1 + logvar - mu.pow(2) - logvar.exp())
return KLD