I’m seeking advice for a learning rate scheduler while training a Transformer based model. It is my understanding that it is quite possible for the training process to take a very long time ( perhaps > 10k itterations). With such a lengthy training period it becomes difficult to know whether I’m stuck in an intractable situation and should give up, or continue processing. As such, I’ve found that using a simple “reduce on plateau” type learning rate will often shrink to a point that hardly seems useful. So there is some logic, in my thinking, to use a cyclical learning rate when training on something which may last for tens or hundreds of thousands of iterations. Am I correct in that assumption? What is the standard practice for these extremely long training sessions? Are Transformers better suited for one method over another?
This is my current optimizer/scheduler setup…
learn_rate = 4e-3
optimizer = torch.optim.Adam( model.parameters(), lr=learn_rate)
main_scheduler = torch.optim.lr_scheduler.CyclicLR(optimizer, base_lr=1e-6, max_lr=4e-3, step_size_up=20, step_size_down=100, cycle_momentum=False)
So my understanding is that it will start with the small lr=1e-6 and over 20 iterations increase to lr=4e-3 then cycle back to lr=1e-6 over the next 100 iterations, and begin again ad-infinitum.
Something I didn’t expect was to see such a jagged response in the loss curves. Rather than showing a slow, rapid, slow, rapid, etc… rate of learning, it actually appears as though there is a reversal of learning during the first cycle followed by an increased learning during the second cycle. For example, here is a training curve for cross entropy loss on the training class…
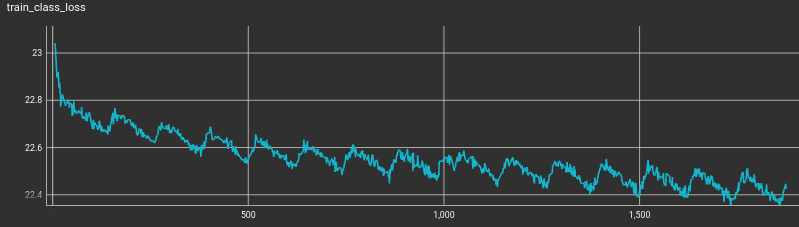
Each of the training loss curves share this characteristic.
Have I, perhaps, made a mistake in my implementation of the scheduler?
Should I not be using the Adam optimizer with the CycleLR scheduler?
Is there a rule of thumb for how long I should let the transformer train before assuming failure?
The training is done in batches of 1000, with approximately 5000 batches in each epoch. So I expect it might be reasonable to take a very long time to learn the data. But is there guidance for what I should actually expect? Do I really let this run for months and still not be sure if it needs more time?
I don’t have the resources of a Google or OpenAI, but is there information on just how long these LLMs took to train? Their batch size, number of batches in an epoch? How many epochs of training? the optimizer and style of learning rate schedules used? That would all be very interesting information for someone trying to work with their own large dataset. My small test datasets work well, but I’m just not sure what to expect when I scale up.