Hi, everyone! I’m currently working on a medical image detection task based on chest X-ray images as my undergraduate final project, in which the dataset is composed of Pneumonia with 4273 images, Normal class with 1583 images, COVID-19 with 576 images, and I used ViT(replicate by myself from scratch) as the model architecture in this project. Above is the basic information of this project. But as the title said, I found that my model cannot learn anything from the dataset through these metrics (confusion matrix, precision, and so on), and then I tried my method from our forum to deal with this problem, some results are shown as the following:
Experiment 1: custom ViT, batch size: 64, learning rate:3e-4, epochs:30.
32 Learning Rate: 0.000300
33 Epoch: 3 | Train Loss: 0.5388, Train Acc: 0.8243, Test Loss: 1.5342, Test Acc: 0.6638, Learning Rate: 0.000300
34 Confusion Matrix:
35 COVID Normal Pneumonia
36 COVID 0 0 116
37 Normal 0 0 317
38 Pneumonia 0 0 855
39 Classification Report:
40 precision recall f1-score support
41 0 0.000000 0.000000 0.000000 116.00000
42 1 0.000000 0.000000 0.000000 317.00000
43 2 0.663820 1.000000 0.797947 855.00000
44 accuracy 0.663820 0.663820 0.663820 0.66382
45 macro avg 0.221273 0.333333 0.265982 1288.00000
46 weighted avg 0.440657 0.663820 0.529693 1288.00000
47 Accuracy Score: 0.6638
48 Learning Rate: 0.000300
49 Epoch: 4 | Train Loss: 0.5498, Train Acc: 0.7905, Test Loss: 1.4384, Test Acc: 0.6638, Learning Rate: 0.000300
50 Confusion Matrix:
51 COVID Normal Pneumonia
52 COVID 0 0 116
53 Normal 0 0 317
54 Pneumonia 0 0 855
55 Classification Report:
56 precision recall f1-score support
57 0 0.000000 0.000000 0.000000 116.00000
58 1 0.000000 0.000000 0.000000 317.00000
59 2 0.663820 1.000000 0.797947 855.00000
60 accuracy 0.663820 0.663820 0.663820 0.66382
61 macro avg 0.221273 0.333333 0.265982 1288.00000
62 weighted avg 0.440657 0.663820 0.529693 1288.00000
63 Accuracy Score: 0.6638
64 Learning Rate: 0.000300
this experiment is an initial experiment without any techniques to deal with the class imbalance issue, my model seems that learned nothing from the dataset. and then after a search, some solutions are: Learning rate, “Model complexity”
“Class imbalance”: before expt 1, I didn’t note my dataset was imbalanced
“Optimizer and loss function choice”: I used the Adam and CrossEntropy as the same as the original paper, so I didn’t pay attention to this part.
and then I continued to other experiments, firstly, I used the lr_scheduler.ReduceLROnPlateau to decrease my lr util 3e-8, the confusion matrix was the same as experiment 1.
Experiment 2: lr_rate:3e-3, others is the same as last experiment, but in this expt, two different kinds of stuff are:
- I used
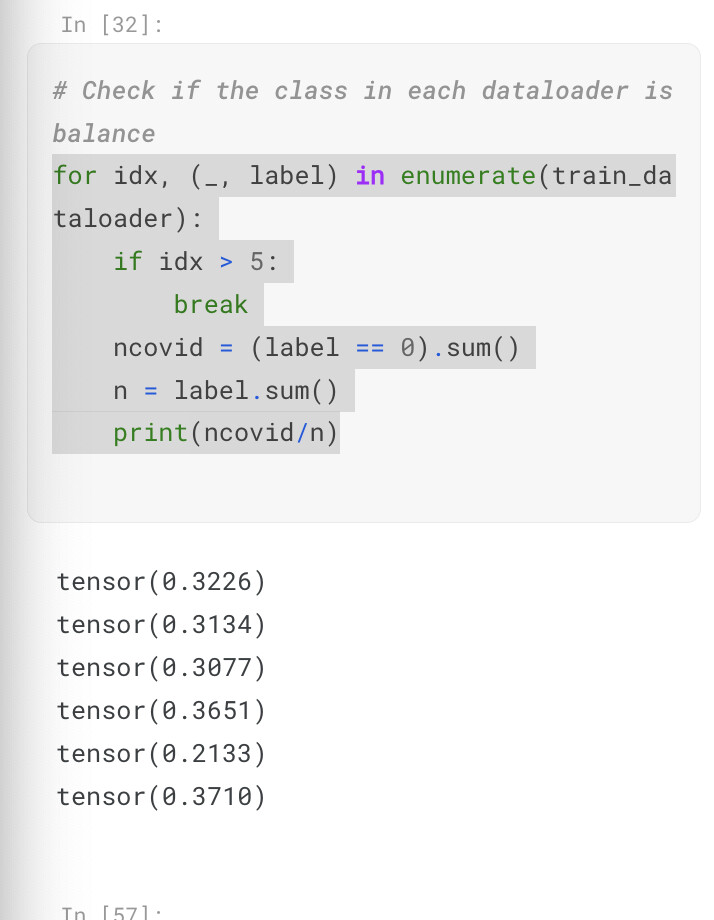
WeightedRandomSamplerin train_dataloader, after this I checked the distribution of the dataloader, the proportion of COVID(minority class)was almost equal to others.
- In the stage of splitting the dataset, I used stratified sampling, which resulted in a good distribution. (no code in this after, I manually calculated the proportion of each class in train_dataset), in this case, i think this part may be okay.
- but the result is not good as the last experiment.
95 Accuracy Score: 0.2436
96 Learning Rate: 0.000300
97 Epoch: 7 | Train Loss: 1.1096, Train Acc: 0.3183, Test Loss: 1.1112, Test Acc: 0.0881, Learning Rate: 0.000300
98 Confusion Matrix:
99 COVID Normal Pneumonia
100 COVID 170 0 0
101 Normal 470 0 0
102 Pneumonia 1289 0 0
103 Classification Report:
104 precision recall f1-score support
105 0 0.088129 1.000000 0.161982 170.000000
106 1 0.000000 0.000000 0.000000 470.000000
107 2 0.000000 0.000000 0.000000 1289.000000
108 accuracy 0.088129 0.088129 0.088129 0.088129
109 macro avg 0.029376 0.333333 0.053994 1929.000000
110 weighted avg 0.007767 0.088129 0.014275 1929.000000
111 Accuracy Score: 0.0881
112 Learning Rate: 0.000300
113 Epoch 00008: reducing learning rate of group 0 to 3.0000e-05.
114 Epoch: 8 | Train Loss: 1.1089, Train Acc: 0.3267, Test Loss: 1.1991, Test Acc: 0.0881, Learning Rate: 0.000030
115 Confusion Matrix:
116 COVID Normal Pneumonia
117 COVID 170 0 0
118 Normal 470 0 0
119 Pneumonia 1289 0 0
120 Classification Report:
121 precision recall f1-score support
122 0 0.088129 1.000000 0.161982 170.000000
123 1 0.000000 0.000000 0.000000 470.000000
124 2 0.000000 0.000000 0.000000 1289.000000
125 accuracy 0.088129 0.088129 0.088129 0.088129
126 macro avg 0.029376 0.333333 0.053994 1929.000000
127 weighted avg 0.007767 0.088129 0.014275 1929.000000
128 Accuracy Score: 0.0881
129 Learning Rate: 0.000030
130 Epoch: 9 | Train Loss: 1.1058, Train Acc: 0.3155, Test Loss: 1.0895, Test Acc: 0.6682, Learning Rate: 0.000030
131 Confusion Matrix:
132 COVID Normal Pneumonia
133 COVID 0 0 170
134 Normal 0 0 470
135 Pneumonia 0 0 1289
Code:
dataset = torchvision.datasets.ImageFolder(data_path, transform=common_transform)
train_dataset, test_dataset = torch.utils.data.random_split(dataset,[0.7, 0.3])
# Deal with Imbalanced Dataset
class_weights={}
for root, sudir, files in os.walk(data_path):
if files:
class_weights[dataset.class_to_idx[os.path.basename(root)]] = len(files)
print(class_weights) # output:{1: 1583, 2: 4273, 0: 576}
sample_weights = [0] * len(train_dataset)
for idx, (data, label) in enumerate(train_dataset):
class_weight = class_weights[label]
sample_weights[idx] = 1/class_weight
sampler = WeightedRandomSampler(sample_weights, num_samples=len(sample_weights), replacement=True)
train_dataloader = DataLoader(train_dataset,
batch_size=batch_size,
sampler=sampler)
test_dataloader = DataLoader(test_dataset,
batch_size=batch_size)
Note:
class_to_idx = (COVID:0, NORMAL:1, PNEUMONIA:2}- After this expt, I thought the reason of the output was still is the same as the expt without weighted sampling may due to the order of sample_weights being incorrect, but eventually no error on that.
- there are differences in this case, as you can see, the model always overrepresented a specific class in each epoch. I have no idea why this situation appeared after the two techniques I mentioned above were used in this experiment, and I checked the experiment simultaneously. And then I tried changing the lr using lr_scheduler as well, but nothing new. someone mentioned that combining the weightedSampling and specifying the weights for the loss function is a recommended method, so I continued to the next experiment.
experiment 4:
Parameters:
config:{batch_size:64
Dataset:"dataset with weighted Sampling and class weight in loss function"
epochs:50
image_size:224
initial_learning_rate:0.0003
mlp_dropout:0.1
model_name:"ViT"
transformer_layers:12}
Result:
1 Epoch: 1 | Train Loss: 0.9572, Train Acc: 0.3302, Test Loss: 1.4187, Test Acc: 0.0876, Learning Rate: 0.000300
2 Confusion Matrix:
3 COVID Normal Pneumonia
4 COVID 169 1 0
5 Normal 470 0 0
6 Pneumonia 1286 3 0
7 Classification Report:
8 precision recall f1-score support
9 0 0.087792 0.994118 0.161337 170.00000
10 1 0.000000 0.000000 0.000000 470.00000
11 2 0.000000 0.000000 0.000000 1289.00000
12 accuracy 0.087610 0.087610 0.087610 0.08761
13 macro avg 0.029264 0.331373 0.053779 1929.00000
14 weighted avg 0.007737 0.087610 0.014218 1929.00000
15 Accuracy Score: 0.0876
16 Learning Rate: 0.000300
17 Epoch: 2 | Train Loss: 0.8471, Train Acc: 0.3275, Test Loss: 1.3836, Test Acc: 0.0881, Learning Rate: 0.000300
18 Confusion Matrix:
19 COVID Normal Pneumonia
20 COVID 170 0 0
21 Normal 470 0 0
22 Pneumonia 1289 0 0
23 Classification Report:
24 precision recall f1-score support
25 0 0.088129 1.000000 0.161982 170.000000
26 1 0.000000 0.000000 0.000000 470.000000
27 2 0.000000 0.000000 0.000000 1289.000000
28 accuracy 0.088129 0.088129 0.088129 0.088129
29 macro avg 0.029376 0.333333 0.053994 1929.000000
30 weighted avg 0.007767 0.088129 0.014275 1929.000000
31 Accuracy Score: 0.0881
32 Learning Rate: 0.000300
33 Epoch: 3 | Train Loss: 0.8325, Train Acc: 0.3444, Test Loss: 1.4703, Test Acc: 0.0881, Learning Rate: 0.000300
34 Confusion Matrix:
35 COVID Normal Pneumonia
36 COVID 170 0 0
37 Normal 470 0 0
38 Pneumonia 1289 0 0
39 Classification Report:
40 precision recall f1-score support
41 0 0.088129 1.000000 0.161982 170.000000
42 1 0.000000 0.000000 0.000000 470.000000
..............(same as above)
Code:
# Calculating weights: inverse of class frequencies
total_samples = 576 + 1583 + 4273
weights = torch.tensor([total_samples / 576, total_samples / 1583, total_samples / 4273], dtype=torch.float32)
loss_function = torch.nn.CrossEntropyLoss(weights).to(device)
optimizer = torch.optim.Adam(params=vit_model_own.parameters(),
lr=learning_rate,
betas=(0.9, 0.999),
weight_decay=weight_decay_optimizer)
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer,patience=5,threshold=0.1,verbose="True")
Model Summary:
==========================================================================================
Layer (type:depth-idx) Param #
==========================================================================================
ViT 152,064
├─Dropout: 1-1 --
├─PatchEmbedding: 1-2 --
│ └─Conv2d: 2-1 590,592
│ └─Flatten: 2-2 --
├─Sequential: 1-3 --
│ └─TransformerEncoderBlock: 2-3 --
│ │ └─MultiheadSelfAttentionBlock: 3-1 2,363,904
│ │ └─MLPBlock: 3-2 4,723,968
│ └─TransformerEncoderBlock: 2-4 --
│ │ └─MultiheadSelfAttentionBlock: 3-3 2,363,904
│ │ └─MLPBlock: 3-4 4,723,968
│ └─TransformerEncoderBlock: 2-5 --
│ │ └─MultiheadSelfAttentionBlock: 3-5 2,363,904
│ │ └─MLPBlock: 3-6 4,723,968
│ └─TransformerEncoderBlock: 2-6 --
│ │ └─MultiheadSelfAttentionBlock: 3-7 2,363,904
│ │ └─MLPBlock: 3-8 4,723,968
│ └─TransformerEncoderBlock: 2-7 --
│ │ └─MultiheadSelfAttentionBlock: 3-9 2,363,904
│ │ └─MLPBlock: 3-10 4,723,968
│ └─TransformerEncoderBlock: 2-8 --
│ │ └─MultiheadSelfAttentionBlock: 3-11 2,363,904
│ │ └─MLPBlock: 3-12 4,723,968
│ └─TransformerEncoderBlock: 2-9 --
│ │ └─MultiheadSelfAttentionBlock: 3-13 2,363,904
│ │ └─MLPBlock: 3-14 4,723,968
│ └─TransformerEncoderBlock: 2-10 --
│ │ └─MultiheadSelfAttentionBlock: 3-15 2,363,904
│ │ └─MLPBlock: 3-16 4,723,968
│ └─TransformerEncoderBlock: 2-11 --
│ │ └─MultiheadSelfAttentionBlock: 3-17 2,363,904
│ │ └─MLPBlock: 3-18 4,723,968
│ └─TransformerEncoderBlock: 2-12 --
│ │ └─MultiheadSelfAttentionBlock: 3-19 2,363,904
│ │ └─MLPBlock: 3-20 4,723,968
│ └─TransformerEncoderBlock: 2-13 --
│ │ └─MultiheadSelfAttentionBlock: 3-21 2,363,904
│ │ └─MLPBlock: 3-22 4,723,968
│ └─TransformerEncoderBlock: 2-14 --
│ │ └─MultiheadSelfAttentionBlock: 3-23 2,363,904
│ │ └─MLPBlock: 3-24 4,723,968
├─Sequential: 1-4 --
│ └─LayerNorm: 2-15 1,536
│ └─Linear: 2-16 2,307
==========================================================================================
Total params: 85,800,963
Trainable params: 85,800,963
Non-trainable params: 0
==========================================================================================
After experiment 3, I tried to use TinyVGG to classify it as well, the result is the same. I felt I was cooked, and too many factors will lead to failure because I’m so new to this area, I thought I may not understand what was going on even from the beginning. I’m not sure whether I provided all the necessary information, leave a comment please if not.
Looking forward to your help!!!