Hi everyone! 
Could you help me with the following issue, please?
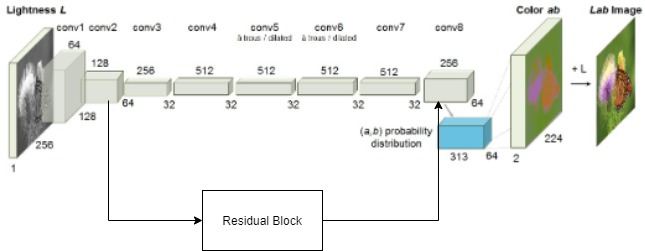
My network architecture is a basic CNN, but I placed a residual block to see how the model would perform. The loss value does not decrease and I don’t know what the problem is.
For the residual block, I am getting the conv2(128 layers) and using it as input to the residual block. The output from the residual block, I am concatenating with the conv8(128 layers) resulting in a tensor of 256 layers.
Am I using the residual block in a correct way?
Here is the model architecture:
# Imports
import torch
import torch.nn as nn
from torchvision import models
import torch.nn.functional as F
class ScaleLayer(nn.Module):
def __init__(self, init_value=1e-3):
super().__init__()
self.scale = nn.Parameter(torch.FloatTensor([init_value]))
def forward(self, input):
return input * self.scale
def weights_init(model):
if type(model) in [nn.Conv2d, nn.Linear]:
nn.init.xavier_normal_(model.weight.data)
nn.init.constant_(model.bias.data, 0.1)
class ResidualBlock(nn.Module):
def __init__(self):
super(ResidualBlock, self).__init__()
self.conv1 = nn.Sequential(
# conv1
nn.Conv2d(in_channels = 128, out_channels = 128, kernel_size = 3, stride = 1, padding = 1),
nn.ReLU(),
nn.Conv2d(in_channels = 128, out_channels = 128, kernel_size = 3, stride = 1, padding = 1),
nn.ReLU(),
nn.Conv2d(in_channels = 128, out_channels = 128, kernel_size = 3, stride = 1, padding = 1),
nn.ReLU(),
nn.BatchNorm2d(num_features = 128),
)
def forward(self, x):
conv1=self.conv1(x)
return conv1
class Color_model(nn.Module):
def __init__(self):
super(Color_model, self).__init__()
self.residual_block = ResidualBlock().cuda()
self.conv1 = nn.Sequential(
# conv1
nn.Conv2d(in_channels = 1, out_channels = 64, kernel_size = 3, stride = 1, padding = 1),
nn.ReLU(),
nn.Conv2d(in_channels = 64, out_channels = 64, kernel_size = 3, stride = 2, padding = 1),
nn.ReLU(),
nn.BatchNorm2d(num_features = 64),
)
self.conv2 = nn.Sequential(
# conv2
nn.Conv2d(in_channels = 64, out_channels = 128, kernel_size = 3, stride = 1, padding = 1),
nn.ReLU(),
nn.Conv2d(in_channels = 128, out_channels = 128, kernel_size = 3, stride = 2, padding = 1),
nn.ReLU(),
nn.BatchNorm2d(num_features = 128),
)
self.conv3 = nn.Sequential(
# conv3
nn.Conv2d(in_channels = 128, out_channels = 256, kernel_size = 3, stride = 1, padding = 1),
nn.ReLU(),
nn.Conv2d(in_channels = 256, out_channels = 256, kernel_size = 3, stride = 1, padding = 1),
nn.ReLU(),
nn.Conv2d(in_channels = 256, out_channels = 256, kernel_size = 3, stride = 2, padding = 1),
nn.ReLU(),
nn.BatchNorm2d(num_features = 256),
)
self.conv4 = nn.Sequential(
# conv4
nn.Conv2d(in_channels = 256, out_channels = 512, kernel_size = 3, stride = 1, padding = 1),
nn.ReLU(),
nn.Conv2d(in_channels = 512, out_channels = 512, kernel_size = 3, stride = 1, padding = 1),
nn.ReLU(),
nn.Conv2d(in_channels = 512, out_channels = 512, kernel_size = 3, stride = 1, padding = 1),
nn.ReLU(),
nn.BatchNorm2d(num_features = 512),
)
self.conv5 = nn.Sequential(
# conv5
nn.Conv2d(in_channels = 512, out_channels = 512, kernel_size = 3, stride = 1, padding = 2, dilation = 2),
nn.ReLU(),
nn.Conv2d(in_channels = 512, out_channels = 512, kernel_size = 3, stride = 1, padding = 2, dilation = 2),
nn.ReLU(),
nn.Conv2d(in_channels = 512, out_channels = 512, kernel_size = 3, stride = 1, padding = 2, dilation = 2),
nn.ReLU(),
nn.BatchNorm2d(num_features = 512),
)
self.conv6 = nn.Sequential(
# conv6
nn.ReLU(),
nn.Conv2d(in_channels = 512, out_channels = 512, kernel_size = 3, stride = 1, padding = 2, dilation = 2),
nn.ReLU(),
nn.Conv2d(in_channels = 512, out_channels = 512, kernel_size = 3, stride = 1, padding = 2, dilation = 2),
nn.ReLU(),
nn.Conv2d(in_channels = 512, out_channels = 512, kernel_size = 3, stride = 1, padding = 2, dilation = 2),
nn.ReLU(),
nn.BatchNorm2d(num_features = 512),
)
self.conv7 = nn.Sequential(
# conv7
nn.Conv2d(in_channels = 512, out_channels = 256, kernel_size = 3, stride = 1, padding = 1, dilation = 1),
nn.ReLU(),
nn.Conv2d(in_channels = 256, out_channels = 256, kernel_size = 3, stride = 1, padding = 1, dilation = 1),
nn.ReLU(),
nn.Conv2d(in_channels = 256, out_channels = 256, kernel_size = 3, stride = 1, padding = 1, dilation = 1),
nn.ReLU(),
nn.BatchNorm2d(num_features = 256),
)
self.conv8 = nn.Sequential(
# conv8
nn.ConvTranspose2d(in_channels = 256, out_channels = 128, kernel_size = 4, stride = 2, padding = 1, dilation = 1),
nn.ReLU(),
nn.Conv2d(in_channels = 128, out_channels = 128, kernel_size = 3, stride = 1, padding = 1, dilation = 1),
nn.ReLU(),
nn.Conv2d(in_channels = 128, out_channels = 128, kernel_size = 3, stride = 1, padding = 1, dilation = 1),
nn.ReLU(),
)
# self.conv9 = nn.Sequential(
# # conv9
# nn.ConvTranspose2d(in_channels = 128, out_channels = 64, kernel_size = 4, stride = 2, padding = 1, dilation = 1),
# nn.ReLU(),
# nn.Conv2d(in_channels = 64, out_channels = 64, kernel_size = 3, stride = 1, padding = 1, dilation = 1),
# nn.ReLU(),
# nn.Conv2d(in_channels = 64, out_channels = 64, kernel_size = 3, stride = 1, padding = 1, dilation = 1),
# nn.ReLU(),
# )
# self.conv10 = nn.Sequential(
# # conv10
# nn.ConvTranspose2d(in_channels = 64, out_channels = 64, kernel_size = 4, stride = 2, padding = 1, dilation = 1),
# nn.ReLU(),
# nn.Conv2d(in_channels = 64, out_channels = 64, kernel_size = 3, stride = 1, padding = 1, dilation = 1),
# nn.ReLU(),
# nn.Conv2d(in_channels = 64, out_channels = 64, kernel_size = 3, stride = 1, padding = 1, dilation = 1),
# nn.ReLU(),
# )
self.conv8_313 = nn.Sequential(
# conv8_313
nn.Conv2d(in_channels = 256, out_channels = 313, kernel_size = 1, stride = 1, dilation = 1),
nn.ReLU()
)
#self.conv8_313 = nn.Conv2d(in_channels = 128, out_channels = 313, kernel_size = 1, stride = 1, dilation = 1)
self.apply(weights_init)
def forward(self, gray_image):
conv1=self.conv1(gray_image)
conv2=self.conv2(conv1)
conv2_residual = self.residual_block(conv2)
conv3=self.conv3(conv2)
conv4=self.conv4(conv3)
conv5=self.conv5(conv4)
conv6=self.conv6(conv5)
conv7=self.conv7(conv6)
conv8=torch.cat((self.conv8(conv7),conv2_residual), 1)
# conv9=self.conv9(conv8)
# conv10=self.conv10(conv9)
features = self.conv8_313(conv8)
return features
# conv1 torch.Size([1, 64, 112, 112])
# conv2 torch.Size([1, 128, 56, 56])
# conv3 torch.Size([1, 256, 28, 28])
# conv4 torch.Size([1, 512, 28, 28])
# conv5 torch.Size([1, 512, 28, 28])
# conv6 torch.Size([1, 512, 28, 28])
# conv7 torch.Size([1, 256, 28, 28])
# conv8 torch.Size([1, 128, 56, 56])
# features torch.Size([1, 313, 56, 56])
And here are the loss values through 30 epochs. I cancelled the training when I saw that the loss value does not decrease.
Epoch [1/180], Epoch Loss: 129.40, Learning Rate: [0.1]
Epoch [2/180], Epoch Loss: 2.9342, Learning Rate: [0.1]
Epoch [3/180], Epoch Loss: 2.9005, Learning Rate: [0.1]
Epoch [4/180], Epoch Loss: 2.8906, Learning Rate: [0.1]
Epoch [5/180], Epoch Loss: 2.8772, Learning Rate: [0.1]
Epoch [6/180], Epoch Loss: 2.8853, Learning Rate: [0.1]
Epoch [7/180], Epoch Loss: 2.8984, Learning Rate: [0.1]
Epoch [8/180], Epoch Loss: 2.8762, Learning Rate: [0.1]
Epoch [9/180], Epoch Loss: 2.8748, Learning Rate: [0.1]
Epoch [10/180], Epoch Loss: 2.8687, Learning Rate: [0.1]
Epoch [11/180], Epoch Loss: 2.8682, Learning Rate: [0.1]
Epoch [12/180], Epoch Loss: 2.8680, Learning Rate: [0.1]
Epoch [13/180], Epoch Loss: 2.8691, Learning Rate: [0.1]
Epoch [14/180], Epoch Loss: 2.8468, Learning Rate: [0.1]
Epoch [15/180], Epoch Loss: 2.8512, Learning Rate: [0.1]
Epoch [16/180], Epoch Loss: 2.8595, Learning Rate: [0.1]
Epoch [17/180], Epoch Loss: 2.8543, Learning Rate: [0.1]
Epoch [18/180], Epoch Loss: 2.8372, Learning Rate: [0.1]
Epoch [19/180], Epoch Loss: 2.8519, Learning Rate: [0.1]
Epoch [20/180], Epoch Loss: 2.8344, Learning Rate: [0.1]
Epoch [21/180], Epoch Loss: 21.456, Learning Rate: [0.1]
Epoch [22/180], Epoch Loss: 5.7463, Learning Rate: [0.1]
Epoch [23/180], Epoch Loss: 5.7368, Learning Rate: [0.1]
Epoch [24/180], Epoch Loss: 5.7448, Learning Rate: [0.1]
Epoch [25/180], Epoch Loss: 5.7260, Learning Rate: [0.1]
Epoch [26/180], Epoch Loss: 5.7462, Learning Rate: [0.1]
Epoch [27/180], Epoch Loss: 5.7462, Learning Rate: [0.1]
Epoch [28/180], Epoch Loss: 5.7462, Learning Rate: [0.1]
Epoch [29/180], Epoch Loss: 5.7462, Learning Rate: [0.1]
Epoch [30/180], Epoch Loss: 5.7462, Learning Rate: [0.1]
Best regards,
Matheus Santos.