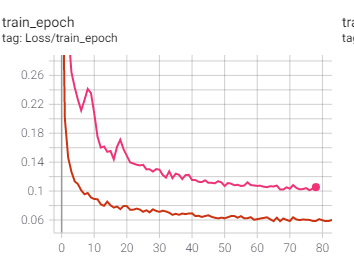
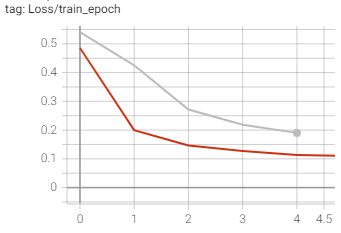
I trained a 3D unet model by Pytorch 1.1.0 Distributed Data Parallel. The test result is good. But after I update Pytorch to V1.7.0. Same code different result. Anyone can help me with that? Is it a syncbatchnorm problem or what?
Even if I finetune the pretrained model(on 1.1.0). Both losses during training and validation increased a lot using v1.7.0.
I only tested on DDP. Because my input data is too large to put in single GPU. So I have to use DDP with syncbatchnorm.
P.S. Could it be a cuda version problem? I used Pytorch1.7+cu101, however my server still using cuda10.
It’s unclear where the difference is coming from and I would recommend to check the loss curves on a single GPU first (by reducing the batch size or slimming down the model).
The next steps depend on the outcome of this run (e.g. using DDP again and removing SyncBN etc.).
The input data is too large that it can only fit into GPU with batchsize=1. This is why I have to choose syncbatchnorm with DDP to simulate larger batchsize. By the way, groupnorm took much more GPU memory(Why I didn’t use it.). Do you have any idea where should I check first except for try single GPU?