Hi all,
I need a bit of help with my PyTorch code. What I am trying to do is to share the weights in the last layer that connects to the output layer while the bias should still be independent.
I.e., what I am trying to do is to duplicate the weights in one row of the weight matrix of the last fully connected layer over the number of output units. E.g., suppose the last hidden layer and the output layer look like this:
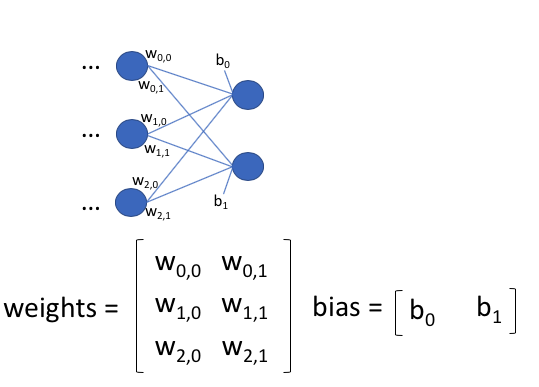
What I want to achieve is that these weights are the same:
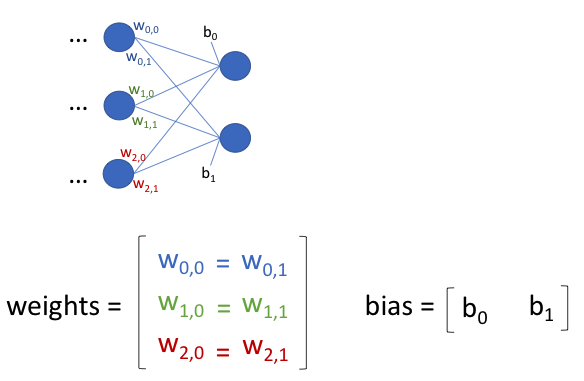
Suppose I have a convolutional neural network like this:
class ConvNet(torch.nn.Module):
def __init__(self, num_classes):
super(ConvNet, self).__init__()
self.conv_1 = torch.nn.Conv2d(in_channels=3,
out_channels=20,
kernel_size=(5, 5),
stride=(1, 1))
self.conv_2 = torch.nn.Conv2d(in_channels=20,
out_channels=40,
kernel_size=(7, 7),
stride=(1, 1),
padding=1)
self.conv_3 = torch.nn.Conv2d(in_channels=40,
out_channels=80,
kernel_size=(11, 11),
stride=(1, 1),
padding=0)
###############################################
self.linear_1 = torch.nn.Linear(1*1*80, num_classes)
# Weight sharing
self.linear_1.weight[1:] = self.linear_1.weight[0]
def forward(self, x):
out = self.conv_1(x)
out = F.relu(out)
out = F.max_pool2d(out, kernel_size=(2, 2), stride=(2, 2))
out = self.conv_2(out)
out = F.relu(out)
out = F.max_pool2d(out, kernel_size=(2, 2), stride=(2, 2))
out = self.conv_3(out)
out = F.relu(out)
out = F.max_pool2d(out, kernel_size=(2, 2), stride=(2, 2))
logits = self.linear_1(out.view(-1, 1*1*80))
probas = F.softmax(logits, dim=1)
return logits, probas
I thought I could maybe achieve this by setting
# Weight sharing
self.linear_1.weight[1:].requires_grad = False
self.linear_1.weight[1:] = self.linear_1.weight[0]
or
# Weight sharing
self.linear_1.weight[1:] = self.linear_1.weight[0]
as shown in the code example above. Unfortunately, this throws an ValueError: can't optimize a non-leaf Tensor.
Another thing I tried was
# Weight sharing
self.linear_1.weight[1:] = self.linear_1.weight[1:].detach()
self.linear_1.weight[1:]= self.linear_1.weight[0].detach()
But this yields the same error.
Does anyone have an idea how I could achieve this weight sharing in the last layer? I would really appreciate it!