Hi guys,
I want to implement some linear layers in each output layer after each convulitonal layer in yolov5. The problem I’m facing is that the input image passed to my linear layer changes each image, due to the fact that yolo localization grid passes each image with a new width and height. Also, I want to train everything with my GPU, which means I need to intialize my linearity layers in the init function of my class:
https://forums.pytorchlightning.ai/t/runtimeerror-but-found-at-least-two-devices-cpu-and-cuda-0/1634
class STN_8_8(nn.Module):
def __init__(self, c1):
super(STN_8_8, self).__init__()
self.Linearity = nn.Sequential(
nn.Linear(c1*16*16, 256),
nn.ReLU(),
nn.Linear(256, 128),
nn.ReLU(),
nn.Linear(128, 64),
nn.ReLU(),
nn.Linear(64, 32),
nn.ReLU(),
nn.Linear(32, 6)
)
# Spatial transformer network forward function
def forward(self, x):
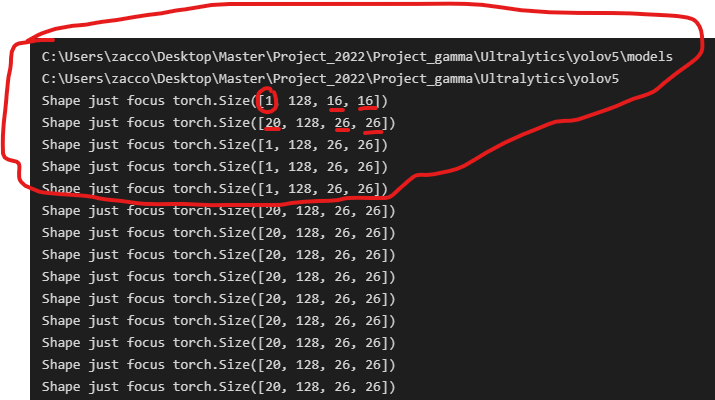
print(f'Shape just focus {x.shape}')
xs = x.view(-1, x.shape[1] * x.shape[2] * x.shape[3])
theta = self.Linearity(xs)
x = theta.view(-1, 2, 3)
return x
The problem that i’m facing is that the network that was implemented before my network forward to my network an input with standard batch size and number of channels but only the width and the height are gettint changed.
The first image works fine and I have no problems. The burner size of the first image is [100, 512, 16, 16].
As soon as my model starts with the next image torch.size[100, 512, 8, 8], I get this error:
"Traceback (most recent call last):\n", " File \"C:\\Users\\zacco\\Desktop\\Master\\Project_2022\\Project_gamma\\Ultralytics\\yolov5\\train.py\", line 677, in <module>\n", " main(opt)\n", " File \"C:\\Users\\zacco\\Desktop\\Master\\Project_2022\\Project_gamma\\Ultralytics\\yolov5\\train.py\", line 571, in main\n", " train(opt.hyp, opt, device, callbacks)\n", " File \"C:\\Users\\zacco\\Desktop\\Master\\Project_2022\\Project_gamma\\Ultralytics\\yolov5\\train.py\", line 352, in train\n", " pred = model(imgs) # forward\n", " File \"c:\\Users\\zacco\\anaconda3\\envs\\pytorch\\lib\\site-packages\\torch\\nn\\modules\\module.py\", line 1110, in _call_impl\n", " return forward_call(*input, **kwargs)\n", " File \"C:\\Users\\zacco\\Desktop\\Master\\Project_2022\\Project_gamma\\Ultralytics\\yolov5\\models\\yolo.py\", line 155, in forward\n", " return self._forward_once(x, profile, visualize) # single-scale inference, train\n", " File \"C:\\Users\\zacco\\Desktop\\Master\\Project_2022\\Project_gamma\\Ultralytics\\yolov5\\models\\yolo.py\", line 179, in _forward_once\n", " x = m(x) # run\n", " File \"c:\\Users\\zacco\\anaconda3\\envs\\pytorch\\lib\\site-packages\\torch\\nn\\modules\\module.py\", line 1110, in _call_impl\n", " return forward_call(*input, **kwargs)\n", " File \"C:\\Users\\zacco\\Desktop\\Master\\Project_2022\\Project_gamma\\Ultralytics\\yolov5\\models\\common.py\", line 60, in forward\n", " theta = self.Linearity(xs)\n", " File \"c:\\Users\\zacco\\anaconda3\\envs\\pytorch\\lib\\site-packages\\torch\\nn\\modules\\module.py\", line 1110, in _call_impl\n", " return forward_call(*input, **kwargs)\n", " File \"c:\\Users\\zacco\\anaconda3\\envs\\pytorch\\lib\\site-packages\\torch\\nn\\modules\\container.py\", line 141, in forward\n", " input = module(input)\n", " File \"c:\\Users\\zacco\\anaconda3\\envs\\pytorch\\lib\\site-packages\\torch\\nn\\modules\\module.py\", line 1110, in _call_impl\n", " return forward_call(*input, **kwargs)\n", " File \"c:\\Users\\zacco\\anaconda3\\envs\\pytorch\\lib\\site-packages\\torch\\nn\\modules\\linear.py\", line 103, in forward\n", " return F.linear(input, self.weight, self.bias)\n", "RuntimeError: mat1 and mat2 shapes cannot be multiplied (60x86528 and 32768x256)\n"
I was able to understand the error, but I was not able to find an idea on how to fulfill my goals with adding a linear layers and using the GPU simulstaniously. This means that I have to implement a variable input for my first linear layer.
i’ll be really greatfull if someone gives me an idea how to deal with such a problem