Hi everybody,
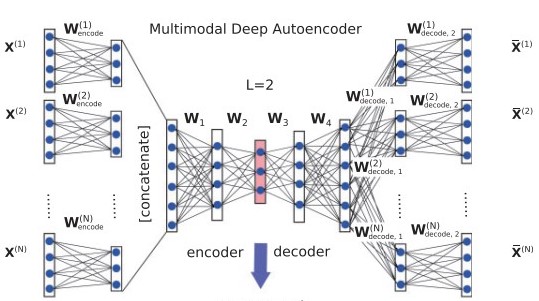
I’m new to pytorch and trying to implement a multimodal deep autoencoder(means: autoencoder with multiple inputs)
At the first all inputs encode with same encoder architecture, after that, all outputs concatenates together and the output goes into the another encoding and deoding layers:
At the end, last decoder layer must reconstruct the inputs as multiple outputs.
Now I have between one and 9 inputs depending on the user’s choice and each input is a 1215x1519 matrix.
I’m rally stuck in first and last layers of this autoencoder.
I have another problem:
Each input is a computed embedding of a graph and as I said before, each input is 1215x1519 matrix.
On the other hand, since we do not have any labels for our data, the original 9x1215x1519 (9 is number of inputs) data considered as label and then considered a noisy version of original data with same shape for model input, in this way we’re trying to reconstruct input according to the labels.
In another implementation of this case with tensorflow and keras, developer fit the model with keras fit() function:
I don’t know what exactly the Keras model is doing, as the fit method doesn’t show any information about the loss function etc.
You could thus check its internal implementation and use the same approach in PyTorch. E.g. if it’s some form of mse loss, use nn.MSELoss in PyTorch to calculate the loss.
I also don’t know what the shape represents in Keras (Is dim0 the batch size? If so, the input shape looks wrong, but I’m also not deeply familiar with Keras) so you should check how each dimension is used inside the model.
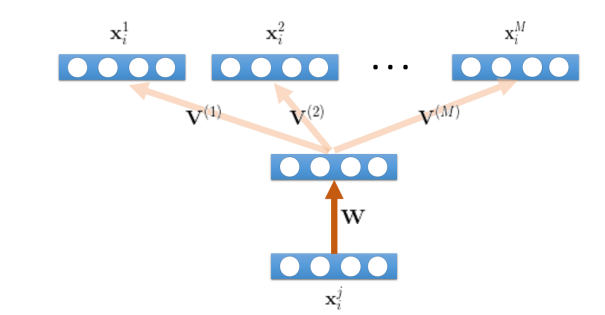
hi @ptrblck , in my case, I have a single encoder (for all domains/classes)and multiple decoders. So is there no way to implement one encoder for multiple inputs or do I have to do it like this case - one encoder for each domain , concatenate/stack them, and pass through the decoder. Then separate the decoder outputs and minimize the reconstruction error? My forward function will look something like this:
One more question is, whatever I told you above - is it implementing the same model that I pasted you above? My only doubt is that in that model there is a single encoder and multiple domain specific decoders whereas the model in this post has multiple encoders to collect inputs.
I honestly don’t know which approach would work the best for your use case (i.e. using multiple or a single shared encoder). Technically, i.e. from the point of view of your PyTorch code, the code looks correct and should work.
Can you please tell me how do I change the code for a single shared encoder? Exactly which lines do I need to change? I want to change the code for a single shared encoder. Thank you!
Hi @ptrblck , there is a small issue here. The code that you provided returns list of tensors with grads. Now, when I try to calculate MSE loss, it gives the following error. What should be the return type here and how do I convert it? to_tensor method don’t work here.
criterion = nn.MSELoss()
loss = criterion(outs,inputs)
AttributeError: ‘list’ object has no attribute ‘size’
hi @ptrblck , can you please clarify one thing in the sample code that you provided - does the “9” represent the number of classes? The input that you provided is 9 * 1 * 4, so is it like you are considering 1 sample from each of the 9 classes and doing SGD? Also, why did you split the decoder out matrix into 3 parts?
No, the 9 represents the number of ecoders as explained in the original question:
Now I have between one and 9 inputs depending on the user’s choice…
I didn’t since out = torch.split(out, 3, dim=1) will create 9 outputs each with a size of 3.
You can just copy/paste my code and add print statements to the forward method to check the shape and content of each tensor if in doubt.
hi @ptrblck , thank you so much! I did the prints and all but was unclear about the numbers. Now, it is much clear to me. Each domain is encoded with one encoder and 3 can be a batch size as inputs.