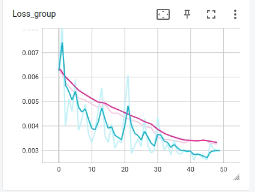
I am training a deep learning model, where the loss vs epochs is plotted for 50 epochs
Training loss at every epoch and validation after every two training epochs.
Blue -training loss
Pink - validation loss
As I see, the training loss is not getting stable.
I have used the pretrained model given by the author on my dataset which is built with the same procedure as given by the author. Technique is also same.
Can I know whether my graph is right or wrong? Should I run it for more epochs or not?
During optimization, your model is traversing something like the above, except with millions of dimensions, instead of just 2. Bound to be some bumps along the way.
Sir, I have one question
As I am running the code given by author, along with pretrained weights given by him on my dataset, Then I applied this generated model at the time of testing then Why the predicted binary masks are not generated corresponding to images at the time of testing. The masks are fully gray colored image. It should be binary mask which will depict the focused region from two images (white-focused,black-defocused)
Where can be the problem?
Either training is not done properly or there is problem in my generated dataset or something else
The author also has trained it for 50 epochs only.
If the problem could be traversed in a straight line, then you wouldn’t need gradient descent, as there would be easier methods of solving the problem.
It’s plausible that the curve is fine. If you’re using cross entropy keep in mind that the function is entirely unbounded. If your epoch-level loss is just averaged across all batches then one sample with a very high loss value could throw the average off.