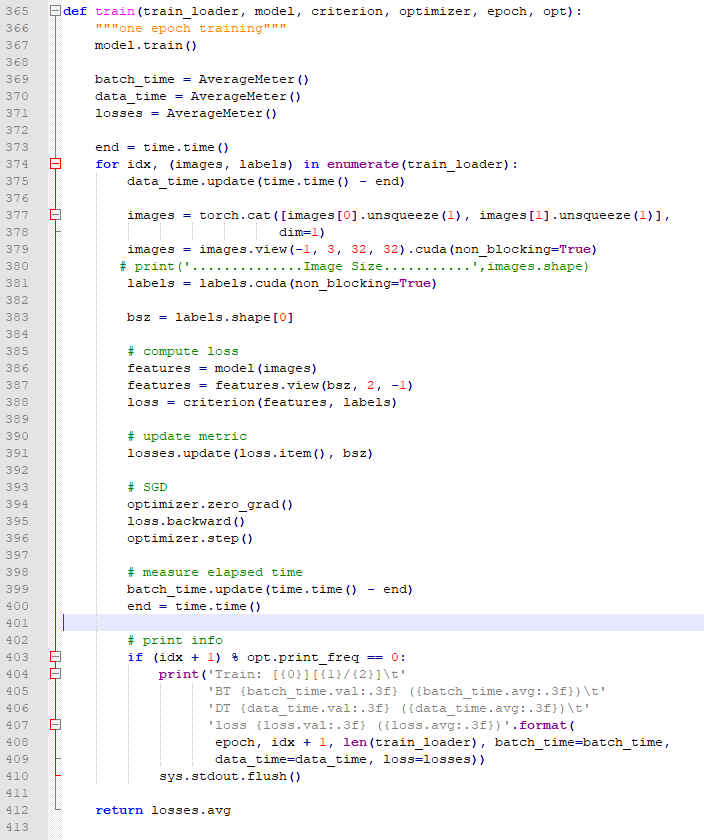
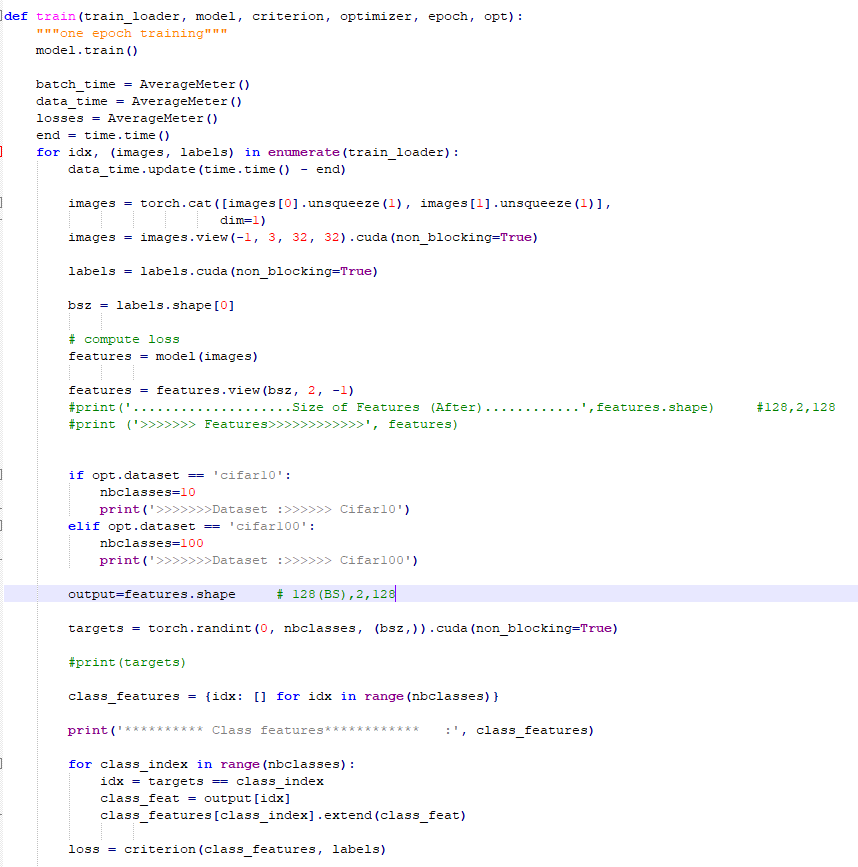
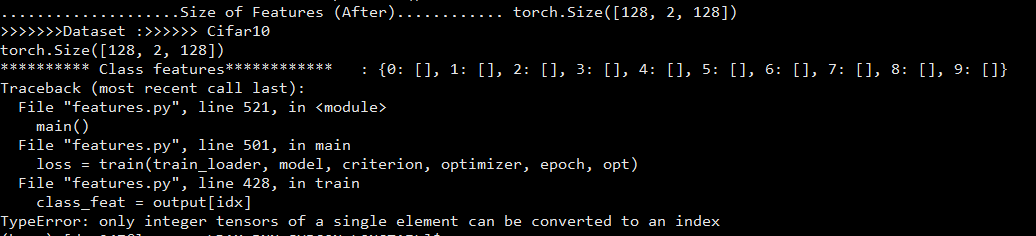
Dear ptrblck,
Thanks for your reply, I have managed to incorporate your code and logic into mine and have executed it successfully with feature dimension of 128,2,128. However, I still can’t understand the logic of calculating the mean values, i.e according to my understanding mean value should be a single value but it displays the following output. It displays such 10 tensors for mean values.
Class Feature Mean…: {0: tensor([[ 1.8197e-01, 2.5143e-02, -1.0864e-04, -7.5293e-02, -6.2245e-02,
6.6454e-02, 2.2286e-02, -3.5217e-02, 5.2823e-02, 2.7451e-02,
8.6874e-02, 5.1490e-02, -6.2997e-02, -6.6158e-02, -9.9687e-02,
9.7800e-02, 5.1059e-02, 5.1787e-02, 2.3591e-02, 2.5489e-02,
2.0475e-01, 6.9972e-02, -5.2651e-02, 6.5951e-02, 4.6435e-02,
-7.2646e-02, -2.6367e-02, 5.7257e-02, -6.5422e-03, -2.4042e-02,
5.7473e-02, 6.9909e-02, -1.8475e-01, 4.5108e-02, -1.8931e-02,
1.1304e-01, -1.4951e-01, 5.7364e-02, 5.5015e-02, 3.4561e-02,
-7.1705e-02, -5.5109e-02, -6.4743e-02, -1.4122e-01, 1.0535e-01,
-4.5873e-02, 2.1184e-02, -5.6603e-02, 2.8610e-02, 1.4033e-01,
5.9965e-03, -4.0568e-03, 1.5643e-02, -1.5262e-01, -1.7967e-02,
1.3538e-01, -8.6360e-02, 1.5044e-01, 6.4374e-02, -1.8130e-01,
-4.8363e-02, -2.3257e-02, -1.8913e-02, -4.0417e-02, -6.0418e-03,
1.0047e-02, 6.2920e-02, -1.4348e-02, -4.8396e-02, 1.4185e-01,
1.3855e-01, -4.7415e-02, 1.1054e-01, -2.4817e-03, 5.2295e-02,
-2.3096e-02, 1.8722e-01, 1.0053e-01, 7.2813e-02, 2.9129e-02,
1.3816e-01, -6.6317e-02, -1.3940e-01, 2.5105e-02, -4.2261e-02,
1.8815e-02, 4.5387e-02, -3.9552e-02, -7.7882e-02, -6.2132e-02,
2.9124e-02, 3.7498e-03, -8.9862e-02, -4.3700e-02, 7.1030e-02,
6.5240e-02, 3.0205e-02, 2.6702e-03, 3.6049e-02, 9.3761e-02,
3.6270e-02, -1.1766e-01, -1.6088e-01, 4.6290e-02, -8.2123e-02,
2.4309e-03, 1.1423e-01, -5.4024e-02, 1.7386e-02, -1.0836e-02,
1.7031e-01, 3.2585e-02, 1.1521e-01, 3.0698e-02, 9.9960e-02,
-1.7035e-02, -7.7930e-02, 1.8263e-01, 1.0334e-01, 1.8118e-01,
4.8566e-02, -7.1670e-02, -1.2270e-01, -1.3332e-01, -1.5380e-02,
-1.5914e-01, -1.0167e-01, 1.1124e-01],
[ 1.8200e-01, 3.9448e-02, 3.7286e-03, -6.7564e-02, -4.8194e-02,
6.0452e-02, 2.4397e-02, -2.2919e-02, 5.0559e-02, 4.2893e-02,
8.5817e-02, 5.7405e-02, -7.3969e-02, -7.0352e-02, -9.5953e-02,
9.1239e-02, 4.4439e-02, 4.9519e-02, 2.0429e-02, 2.1237e-02,
1.9860e-01, 6.6372e-02, -3.8266e-02, 6.7373e-02, 5.0183e-02,
-7.4488e-02, -1.9873e-02, 6.0643e-02, -1.4473e-02, -2.5556e-02,
6.8193e-02, 6.7811e-02, -1.7251e-01, 5.6405e-02, -1.1552e-02,
1.1177e-01, -1.4240e-01, 5.5175e-02, 5.4221e-02, 3.0813e-02,
-6.9005e-02, -5.7479e-02, -5.5988e-02, -1.4929e-01, 1.0589e-01,
-6.4639e-02, 7.6206e-03, -7.1328e-02, 2.3568e-02, 1.5242e-01,
6.8193e-03, 1.3356e-03, 1.5267e-02, -1.5220e-01, -2.4627e-02,
1.2660e-01, -9.6360e-02, 1.3858e-01, 5.2747e-02, -1.8939e-01,
-5.4749e-02, -2.7353e-02, -1.8591e-02, -5.3250e-02, 4.5380e-03,
5.6123e-03, 6.6939e-02, -1.6745e-02, -6.5302e-02, 1.2999e-01,
1.4105e-01, -4.6737e-02, 9.6890e-02, -8.0185e-03, 5.5306e-02,
-2.4646e-02, 1.8729e-01, 1.0327e-01, 5.8818e-02, 2.0035e-02,
1.3873e-01, -7.6202e-02, -1.4655e-01, 3.3630e-02, -6.1461e-02,
2.0106e-02, 3.6875e-02, -5.0162e-02, -8.8452e-02, -6.1024e-02,
4.8275e-02, 1.8975e-02, -9.7968e-02, -3.9750e-02, 6.8793e-02,
5.6112e-02, 3.6727e-02, 4.3991e-03, 2.7574e-02, 9.6684e-02,
4.8077e-02, -1.3928e-01, -1.6517e-01, 4.6624e-02, -8.2189e-02,
-6.7808e-03, 9.8721e-02, -6.0551e-02, 1.1518e-02, -1.7801e-02,
1.7948e-01, 2.1270e-02, 1.1515e-01, 4.2319e-02, 8.7374e-02,
-3.0091e-02, -9.1005e-02, 1.8670e-01, 1.0329e-01, 1.9839e-01,
5.2998e-02, -7.2922e-02, -1.3568e-01, -1.1318e-01, -2.0052e-02,
-1.5237e-01, -9.6367e-02, 1.1343e-01]], device=‘cuda:0’,
grad_fn=), 1: tensor([[ 0.1787, 0.0171, 0.0090, -0.0619, -0.0658, 0.0561, 0.0311, -0.0270,