hi everyone,
I met a strange illegal memory access error during evaluation step. It happens randomly. I don’t think there is anything wrong in my evaluation code.
I was training on 4 GPUs(tesla v100), pytorch 1.6, at the same time I was training with mixed precise by using apex.
the error looks like the following error information:
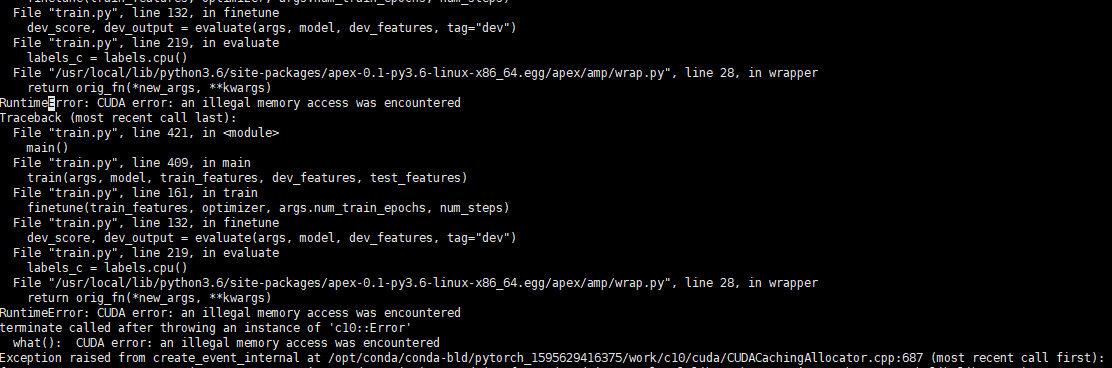
my evaluation code is
def evaluate(args, model, features, tag="dev"):
dev_sampler = torch.utils.data.distributed.DistributedSampler(features)
dataloader = DataLoader(features, batch_size=args.test_batch_size, num_workers=
args.n_gpu, pin_memory=True, shuffle=False, collate_fn=collate_fn, drop_last=True,
sampler=dev_sampler)
preds = []
labels = []
tensor_list_pred = [torch.zeros([int(len(dataloader)*args.test_batch_size), args.num_class],
dtype= torch.float32, device = args.device) for _ in range(args.n_gpu)]
tensor_list_label = [torch.zeros([int(len(dataloader)*args.test_batch_size),args.num_class],
dtype= torch.float32, device = args.device) for _ in range(args.n_gpu)]
for batch in dataloader:
model.eval()
inputs = {'input_ids': batch[0].to(args.device),
'attention_mask': batch[1].to(args.device),
'entity_pos': batch[3],
'hts': batch[4],
}
label = np.array(batch[2])
label_t = torch.from_numpy(label)
label_t = label_t.squeeze(1)
labels.append(label_t.to(args.device))
with torch.no_grad():
pred, *_ = model(**inputs)
pred = pred.cpu().numpy()
pred[np.isnan(pred)] = 0
pred = torch.from_numpy(pred)
preds.append(pred.to(args.device))
label_s = torch.cat(labels, axis=0)
pred_s = torch.cat(preds, axis=0)
dist.all_gather(tensor_list_pred, pred_s)
dist.all_gather(tensor_list_label, label_s)
labels = torch.cat(tensor_list_label, axis=0)
preds = torch.cat(tensor_list_pred, axis=0)
labels_c = labels.cpu()
preds_c = preds.cpu()
r,c = preds_c.size()
_ , index = torch.topk(preds_c, c, dim=1)
pred_nr = index[:,0].numpy()
_ , index_label = torch.topk(labels_c, c, dim=1)
y_true = index_label[:,0].numpy()
f1_macro = f1_score(y_true, pred_nr, average='macro')
f1_micro = f1_score(y_true, pred_nr, average='micro')
f1_weighted = f1_score(y_true, pred_nr, average='weighted')
output = {
tag + "_F1_micro": f1_micro * 100,
tag + "_F1_macro": f1_macro * 100,
tag + "_F1_weighted": f1_weighted * 100,
tag + "_class_report": classification_report(y_true, pred_nr),
}
return f1_weighted, output
I have been stucked here for several days. who can tell me which reason causes this error? Could you give me some suggestions for fixing this problem.
Thanks in advance