I am training a model on top of ALBERT using mixed precision with apex. And the loss keeps decreasing like this
. How can i track the problem? I found there was “nans” in the matrix and i fixed it with LayerNorm as they tend to be very large.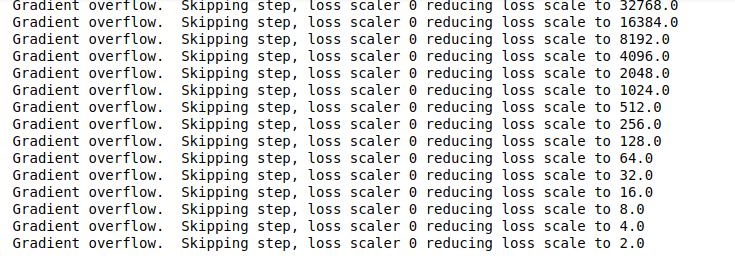
If you see this message every couple of iterations, you can just ignore it.
However, if you encounter any NaN values in your input, this could also create NaNs in your parameters, thus output and you will end up decreasing the loss scaling value until you underflow and divide by zero.
Can the parameters in the model after certain operation cause the gradient to explode that cause overflow ? Or i mainly should debug the input ?
Now there is no NaNs in the output of each layer , however still the loss scaling is decreasing.
If the gradients overflow due to loss scaling, the scaling value will be lowered and you will see this message.
If you encounter a NaN output, something in your model went wrong or the input contained invalid values.
If you see the loss scaling information not in every iteration, you can still ignore it, or are you seeing it in every step?
I see the loss scaling every iteration. And the i print all the matrices , there is not NaNs
Could you check all parameters for NaN or Infs?
Also, how large is your loss?
Loss is extremely large more than 60k and next step 120k and third step 220k. This is kind of weird.
tensor(42380.2852, device=‘cuda:0’, grad_fn=)
tensor(124045.8906, device=‘cuda:0’, grad_fn=)
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 32768.0
tensor(917312., device=‘cuda:0’, grad_fn=)
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 16384.0
tensor(422464., device=‘cuda:0’, grad_fn=)
tensor(129528., device=‘cuda:0’, grad_fn=)
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 8192.0
tensor(nan, device=‘cuda:0’, grad_fn=)
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 4096.0
tensor(nan, device=‘cuda:0’, grad_fn=)
These are the loss values for the first couple of steps
@ptrblck There is something also i found out , i am building a 1D conv over the top of ALBERT model. I tried different combinations while freezing ALBERT. I tried :
1-
There is something also i found out , i am build a 1D conv over the top of ALBERT model. I tried different combinations while freezing ALBERT. I tried :
1-
class Grammer_Classification(nn.Module):
def init(self,Albert):
super(Grammer_Classification,self).init()
self.attn_1 = Self_Attention(2048,2048)
self.conv_1 = Conv1D_Layer(2048,4,1024)
self.attn_2 = Self_Attention(1024,1024)
self.conv_2 = Conv1D_Layer(1024,2,512)
self.FFN1 = nn.Linear(2560,512)
self.Layer_norm = nn.LayerNorm(512,eps=1e-12)
self.FFN2 = nn.Linear(512,2)
def forward(self,X,mask):
X= Albert(X)
#X = X[0].view(X[0].shape[0],-1)
X = self.attn_1(X[0])
X = self.conv_1(X)
X = self.attn_2(X)
X = self.conv_2(X)
X = X.reshape(X.shape[0],X.shape[1]*X.shape[2])
X = F.leaky_relu(self.FFN1(X))
X = self.Layer_norm(X)
X = self.FFN2(X)
return X
2-
class Grammer_Classification(nn.Module):
def init(self,Albert):
super(Grammer_Classification,self).init()
self.attn_1 = Self_Attention(1024,1024)
self.conv_1 = Conv1D_Layer(2048,16,1024)
self.attn_2 = Self_Attention(512,512)
self.conv_2 = Conv1D_Layer(1024,4,512)
self.FFN1 = nn.Linear(94208,1024)
self.Layer_norm = nn.LayerNorm(1024,eps=1e-12)
self.FFN2 = nn.Linear(1024,2)
def forward(self,X,mask):
X= Albert(X)
X = X[0].view(X[0].shape[0],-1)
X = F.leaky_relu(self.FFN1(X))
X = self.Layer_norm(X)
X = self.FFN2(X)
return X
and only conv1D but i deleted the code.
And the accuracy never changes while the loss scaling. Any idea how can i debug this further more ? I printed all the matrices and there are no NaNs except after 30-40 steps
It seems the loss is exploding.
What range does the loss have without using apex or with opt_level='O0'?
Loss start from 6 and at epoch 3 its 13.6. And its increasing and accuracy decreasing. This is without using apex.
Thanks for the update.
Could you try to make sure the FP32 run is working correctly, i.e. the loss is decreasing?
Sometimes you will see an increasing loss if you forgot to zero out the gradients.
I kept changing in the model architecture till this happen.
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 32768.0
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 16384.0
Epoch 1 loss is 14325.70703125 and accuracy is 0.7753031716417911
Epoch 2 loss is 10062.3505859375 and accuracy is 0.8111007462686567
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 8192.0
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 4096.0
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 2048.0
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 1024.0
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 512.0
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 256.0
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 128.0
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 64.0
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 32.0
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 16.0
Epoch 3 loss is 114.29520416259766 and accuracy is 0.8091962064676618
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 8.0
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 4.0
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 2.0
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 1.0
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 0.5
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 0.25
Is this now normal ?
Is your model training correctly using FP32?
The loss scaler should reduce the loss scaling at the beginning, but should eventually stop decreasing the loss continuously.
I would still recommend to make sure the model trains in FP32 and the loss looks reasonable.
The loss looks reasonable in FP32 , however its fluctuating. And the loss scale decrease after 4 epochs.
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 32768.0
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 16384.0
Epoch 1 loss is 14325.70703125 and accuracy is 0.7753031716417911
Epoch 2 loss is 10062.3505859375 and accuracy is 0.8111007462686567
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 8192.0
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 4096.0
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 2048.0
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 1024.0
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 512.0
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 256.0
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 128.0
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 64.0
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 32.0
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 16.0
Epoch 3 loss is 114.29520416259766 and accuracy is 0.8091962064676618
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 8.0
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 4.0
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 2.0
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 1.0
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 0.5
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 0.25
Epoch 4 loss is 4.909278869628906 and accuracy is 0.7796175373134329
Epoch 5 loss is 0.1522625833749771 and accuracy is 0.8130830223880597
Epoch 6 loss is 0.15188875794410706 and accuracy is 0.8128498134328358
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 0.125
Epoch 7 loss is 0.1318310648202896 and accuracy is 0.812616604477612
I am training as we speak. However i think i should change the architecture cause its kind of slow training. I am sure i am using everything multiple of 8
Since the loss downscaling stopped, it could work.
The output of the model during prediction is always the same. Does this has anything to do with loss issue ?
It could mean that your model is overfitting to a specific class.