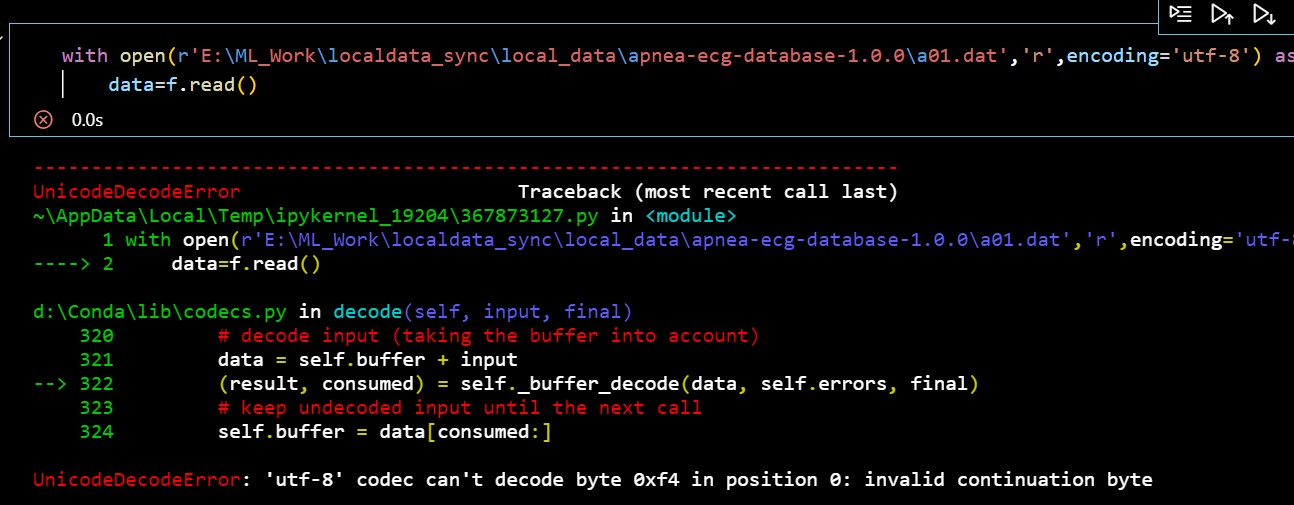
I met a problem when I started to process the apnea-ecg dataset released in 2000. code is shown as follows. If the utf-8 is wrong, how could i know what it is. I have tried utf-16, GBK, wrong either.
i solved my problem. use wfdb package