I have a pytorch model I built for recommending best restaurants to user. I used graphSage and MSE as a loss between the predicted labels and the actual ones.
I want to apply the same loss mentioned on Food Discovery with Uber Eats: Using Graph Learning to Power Recommendations
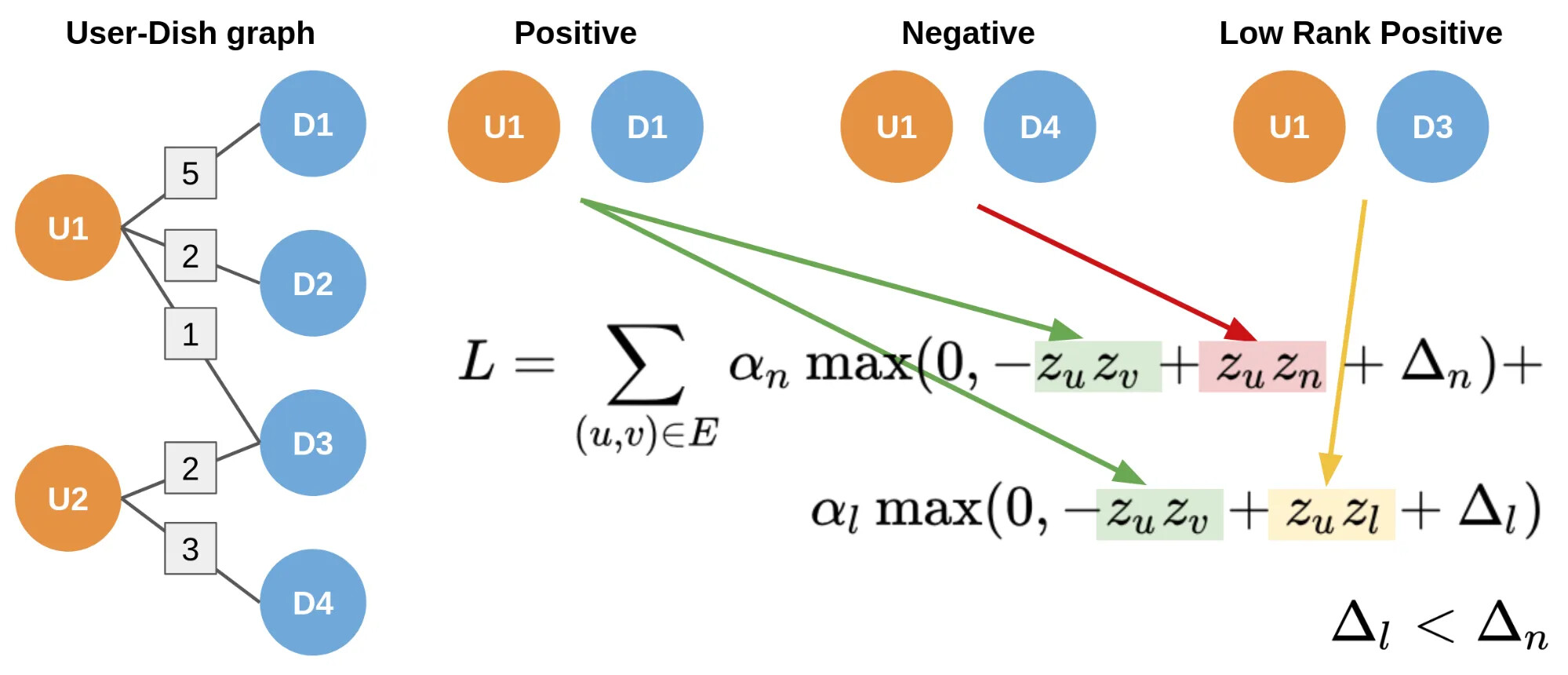
Here’s my code
from torch_geometric.nn import SAGEConv, to_hetero
import torch.nn.functional as F
import torch
import torch.nn as nn
# Our final classifier applies the dot-product between source and destination
# node embeddings to derive edge-level predictions:
class Predicter(torch.nn.Module):
def __init__(self, in_channels, hidden_channels, out_channels, num_layers,dropout):
super(Predicter, self).__init__()
self.lins = nn.ModuleList()
self.lins.append(nn.Linear(in_channels, hidden_channels))
for _ in range(num_layers - 2):
self.lins.append(nn.Linear(hidden_channels, hidden_channels))
self.lins.append(nn.Linear(hidden_channels, out_channels))
self.dropout = dropout
def reset_parameters(self):
for lin in self.lins:
lin.reset_parameters()
def forward(self, x_i, x_j):
x = x_i * x_j
for lin in self.lins[:-1]:
x = lin(x)
x = F.relu(x)
x = F.dropout(x, p=self.dropout, training=self.training)
x = self.lins[-1](x)
return x
# return torch.sigmoid(x)
class GNNStack(torch.nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim, num_layers, dropout, emb=False):
super(GNNStack, self).__init__()
conv_model = SAGEConv
self.convs = nn.ModuleList()
self.convs.append(conv_model(input_dim, hidden_dim))
self.dropout = dropout
self.num_layers = num_layers
self.emb = emb
# Create num_layers GraphSAGE convs
assert (self.num_layers >= 1), 'Number of layers is not >=1'
for l in range(self.num_layers - 1):
self.convs.append(conv_model(hidden_dim, hidden_dim))
# post-message-passing processing
self.post_mp = nn.Sequential(
nn.Linear(hidden_dim, hidden_dim), nn.Dropout(self.dropout),
nn.Linear(hidden_dim, output_dim))
def forward(self, x, edge_index):
for i in range(self.num_layers):
x = self.convs[i](x, edge_index)
x = F.relu(x)
x = F.dropout(x, p=self.dropout, training=self.training)
x = self.post_mp(x)
# Return final layer of embeddings if specified
return x
# Else return class probabilities
# return F.log_softmax(x, dim=1)
def loss(self, pred, label):
return F.nll_loss(pred, label)
class EdgeDecoder(torch.nn.Module):
def __init__(self, hidden_channels):
super().__init__()
self.lin1 = Linear(hidden_channels, hidden_channels)
self.lin2 = Linear(hidden_channels, 1)
def forward(self, x_i, x_j):
x = x_i * x_j
x = self.lin1(x)
x = F.relu(x)
x = self.lin2(x)
return x.view(-1)
class MainModel(torch.nn.Module):
def __init__(self, data, user_input_size,
rest_input_size,
hidden_channels):
super().__init__()
# Since the dataset does not come with rich features, we also learn two
# embedding matrices for users and movies:
self.user_lin = torch.nn.Linear(in_features = user_input_size, out_features = hidden_channels)
self.rest_lin = torch.nn.Linear(in_features = rest_input_size, out_features = hidden_channels)
self.user_emb = torch.nn.Embedding(data["user"].num_nodes, hidden_channels)
self.rest_emb = torch.nn.Embedding(data["restaurant"].num_nodes, hidden_channels)
# Instantiate homogeneous GNN:
self.gnn = GNNStack(hidden_channels, hidden_channels, hidden_channels, 4, 0.3, emb = True)
# Convert GNN model into a heterogeneous variant:
self.gnn = to_hetero(self.gnn, metadata=data.metadata())
self.new_x_dict = None
def forward(self, train_data) -> Tensor:
# `x_dict` holds feature matrices of all node types
# `edge_index_dict` holds all edge indices of all edge types
x_dict = {
"user": self.user_lin(train_data.x_dict["user"]) + self.user_emb(train_data["user"].node_id),
"restaurant": self.rest_lin(train_data.x_dict["restaurant"]) + self.rest_emb(train_data["restaurant"].node_id),
}
self.new_x_dict = self.gnn(x_dict, train_data.edge_index_dict)
return self.new_x_dict
import tqdm
from torch_geometric.utils import negative_sampling, batched_negative_sampling
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
optim_wd = 0
epochs = 20
hidden_dim = 256
dropout = 0.3
num_layers = 2
lr = 0.01
node_emb_dim = 256
model = MainModel(train_data, user_input_size= train_data['user'].x.shape[1],
rest_input_size = train_data['restaurant'].x.shape[1],
hidden_channels=64).to(device)
predicter = EdgeDecoder(hidden_channels = 64).to(device)
optimizer = torch.optim.Adam(
list(model.parameters()) + list(predicter.parameters()),
lr=lr, weight_decay=optim_wd)
losses = []
vallosses=[]
import torch.nn.functional as F
for epoch in range(epochs):
total_loss = 0
for batch in tqdm.tqdm(train_loader):
optimizer.zero_grad()
pos_edges = batch['user', 'rates', 'restaurant'].edge_label_index
labels = batch['user', 'rates', 'restaurant'].edge_label
model.train()
predicter.train()
optimizer.zero_grad()
node_emb = model(batch)
# Predict the class probabilities on the batch of positive edges using link_predictor
# Apply the weight to the positive loss term
pos_pred = predicter(node_emb['user'][pos_edges[0]], node_emb['restaurant'][pos_edges[1]])
loss =F.mse_loss(pos_pred.view(-1).float(), labels)
# Backpropagate and update parameters
loss.backward()
optimizer.step()
total_loss += float(loss)
print(f"Epoch {epoch + 1}: Train loss: {total_loss} ")