For an implementation of a graphical model I need to perform matmul along the axis 1 and 2 of a four-dimensional input tensor. The axis 0 and 3 should be broadcasted. The current implementation of torch matmul performs the matrix multiplication across the final two axis and performs broadcasting across all of input[:-2].
Currently I solve this by first transposing the input and then performing matmul.
input_row = input_col.transpose(1, 3)
message = torch.matmul(self.gaussian, input_row)
However, this is very slow. Profiling indicate that 67% of computational time of the entire model is a contiguous call inside matmul (see below). The only reason this contiguous call is necessary is the transpose right before the matmul, as input_col is contiguous.
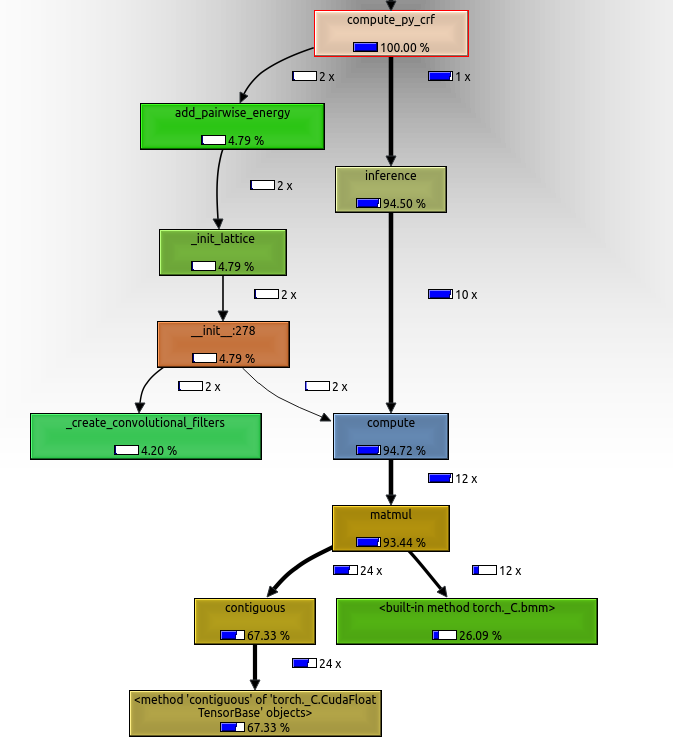
Does anybody know how I can perform this operation without transposing input_col?