Problem
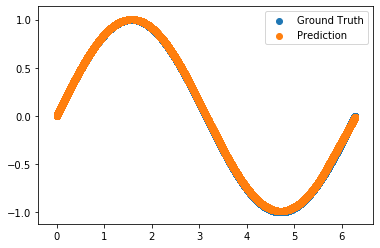
I am trying to build a function approximator using PyTorch. But my neural network does not seem to learn anything.
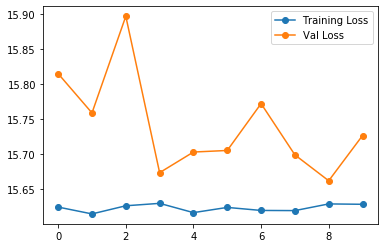
The full executable code is as follows. I am not sure what mistakes I have made. Could someone help me? Thank you in advance.
import torch
import numpy as np
from torch import nn, optim
from torch.nn import functional as F
from torch.utils.data import TensorDataset, DataLoader
from sklearn.model_selection import train_test_split
LR = 1e-6
MAX_EPOCH = 10
BATCH_SIZE = 512
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
class SineApproximator(nn.Module):
def __init__(self):
super(SineApproximator, self).__init__()
self.regressor = nn.Sequential(nn.Linear(1, 1024),
nn.ReLU(inplace=True),
nn.Linear(1024, 1024),
nn.ReLU(inplace=True),
nn.Linear(1024, 1))
def forward(self, x):
output = self.regressor(x)
return x
X = np.random.rand(10**5) * 2 * np.pi
y = np.sin(X)
X_train, X_val, y_train, y_val = map(torch.tensor, train_test_split(X, y, test_size=0.2))
train_dataloader = DataLoader(TensorDataset(X_train.unsqueeze(1), y_train.unsqueeze(1)), batch_size=BATCH_SIZE,
pin_memory=True, shuffle=True)
val_dataloader = DataLoader(TensorDataset(X_val.unsqueeze(1), y_val.unsqueeze(1)), batch_size=BATCH_SIZE,
pin_memory=True, shuffle=True)
model = SineApproximator().to(device)
optimizer = optim.Adam(model.parameters(), lr=LR)
criterion = nn.MSELoss(reduction="mean")
# training loop
train_loss_list = list()
val_loss_list = list()
for epoch in range(MAX_EPOCH):
print("epoch %d / %d" % (epoch+1, MAX_EPOCH))
model.train()
# training loop
temp_loss_list = list()
for X_train, y_train in train_dataloader:
X_train = X_train.type(torch.float32).to(device)
y_train = y_train.type(torch.float32).to(device)
optimizer.zero_grad()
score = model(X_train)
loss = criterion(input=score, target=y_train)
loss.requires_grad = True
loss.backward()
optimizer.step()
temp_loss_list.append(loss.detach().cpu().numpy())
temp_loss_list = list()
for X_train, y_train in train_dataloader:
X_train = X_train.type(torch.float32).to(device)
y_train = y_train.type(torch.float32).to(device)
score = model(X_train)
loss = criterion(input=score, target=y_train)
temp_loss_list.append(loss.detach().cpu().numpy())
train_loss_list.append(np.average(temp_loss_list))
# validation
model.eval()
temp_loss_list = list()
for X_val, y_val in val_dataloader:
X_val = X_val.type(torch.float32).to(device)
y_val = y_val.type(torch.float32).to(device)
score = model(X_val)
loss = criterion(input=score, target=y_val)
temp_loss_list.append(loss.detach().cpu().numpy())
val_loss_list.append(np.average(temp_loss_list))
print("\ttrain loss: %.5f" % train_loss_list[-1])
print("\tval loss: %.5f" % val_loss_list[-1])