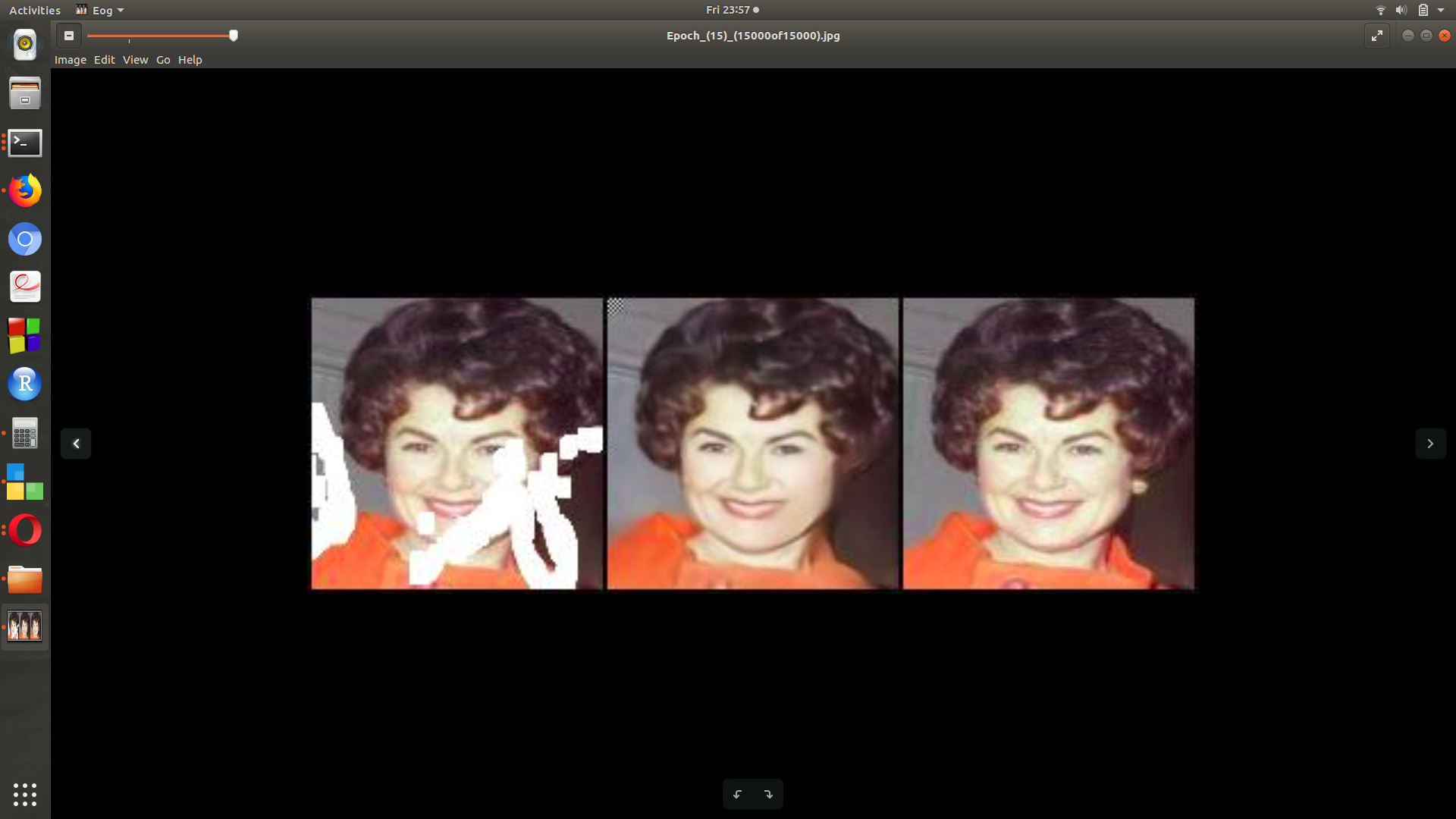
Hi, in GAN results i am getting very weird pixel artifact patch in results… so wanted some ideas how can i get rid it off. Also, wanted to discuss reasons behind such artifacts as well.!
There is a dark spot in the image.
Input image is 1st image, Generated Image is 2nd, and 3rd is GT.
I have seen such artifacts only when discriminator gets trained faster, and it causes model collapse. But, in my case network is still being trained normally with the artifact as well.
The other reason could be overfitting, celebA dataset is well aligned to eyes and nose in same position in almost all images.
while testing I did realize that my GAN learns spatial key points descriptors, it does SOTA results on testing but fails on being presented with images outside from dataset, which gives hint maybe the GAN is over fitting in someway.
On changing dataset loader slightly, the pixel corruption does changes as well.
I am still not sure for the cause of pixel corruption.
Doesn’t model collapse just mean that many images in the starting domain get collapsed to the same image in the output domain? X1->Y1 and X2->Y1 etcetera? I don’t follow how modal collapse has to do with the artifacts… sorry! Could you please explain?
For the task of inpainting, various loss functions have been proposed till now. In the images shown, the black box artifact is present in the area where image data is already available. So ideally you should not get that kind of artifact. I would be interested to know the loss function used. If it was simple L1 between the whole predicted image and gt image, I believe this can happen. One way to handle it using loss function is you calculate loss only for regions which are being filled. So that data which is already available can be used. Something like (mask*predicted) - (mask * GT).
Is this a list of things that people consider to be included in “mode collapse”? I read that it’s #3 but didn’t see the first two included in mode collapse…