Here is the full error TrackBack
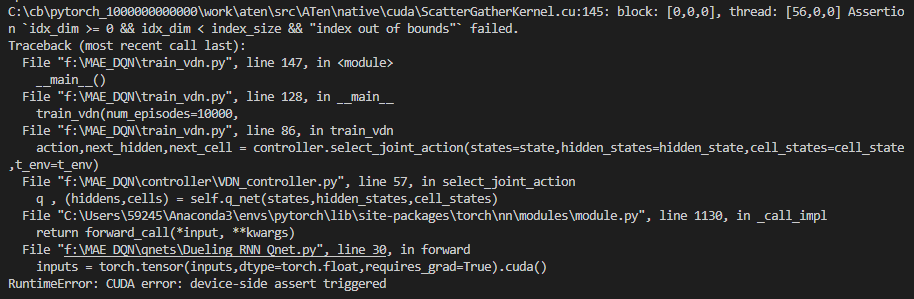
This happens in network update() function, where it attempts to call forward() to compute Q values of the batch of state.
Here’s my network and update() function
Network
class VDNNet(nn.Module):
def __init__(self,state_dim,rnn_hidden_dim,action_dim,num_layers) -> None:
super().__init__()
self.rnn_hidden_dim = rnn_hidden_dim
#------------------------- Common Network -----------------------------
self.fc1 = nn.Linear(state_dim,rnn_hidden_dim)
self.dropout = nn.Dropout()
self.lstm = nn.LSTM(rnn_hidden_dim,rnn_hidden_dim,num_layers=num_layers)
#------------------------- Dueling Network ----------------------------
self.fc_A = nn.Linear(rnn_hidden_dim,action_dim)
self.fc_V = nn.Linear(rnn_hidden_dim,1)
self.weight_init()
def forward(self,inputs,hidden_states,cell_states):
if type(inputs) is not torch.Tensor:
inputs = torch.tensor(inputs,dtype=torch.float,requires_grad=True).cuda()
if type(hidden_states) is not torch.Tensor:
hidden_states = torch.tensor(hidden_states,dtype=torch.float,requires_grad=True).cuda()
cell_states = torch.tensor(cell_states,dtype=torch.float,requires_grad=True).cuda()
if inputs.dim() == 2:
inputs = inputs.unsqueeze(0)
batch_size = inputs.shape[0]
x = self.dropout(inputs)
x = F.relu(self.fc1(x)) # [batch_size,n_agents,state_dim] -> [batch_size,n_agents,rnn_hidden_dim]
outputs = []
hs = []
cs = []
# print(x.shape)
for i in range(batch_size):
output,(h,c) = self.lstm(x,(hidden_states[i],cell_states[i]))
outputs.append(output[i].cpu().detach().numpy())
hs.append(h.cpu().detach().numpy())
cs.append(c.cpu().detach().numpy())
x = torch.tensor(np.array(outputs),dtype=torch.float,requires_grad=True).cuda()
hs = np.array(hs,dtype=np.float32)
cs = np.array(cs,dtype=np.float32)
# x : [batch_size,n_agents,rnn_hidden_dim]
# h : [batch_size,lstm_num_layers,n_agents,rnn_hidden_dim]
# h : [batch_size,lstm_num_layers,n_agents,rnn_hidden_dim]
x = F.relu(x)
A = self.fc_A(F.relu(x)) # [batch_size,n_agents,state_dim] -> [batch_size,n_agents,action_dim]
V = self.fc_V(F.relu(x)) # [batch_size,n_agents,state_dim] -> [batch_size,n_agents,1]
q = V + A - A.mean(dim=2,keepdim=True) # [batch_size,n_agents,action_dim]
return q,(hs,cs) # Return Q-values and (HiddenState,CellState) tuple
def weight_init(self):
self.fc1.weight.data.normal_(0,0.1)
self.fc1.bias.data.zero_()
self.fc_A.weight.data.normal_(0,0.1)
self.fc_A.bias.data.zero_()
self.fc_V.weight.data.normal_(0,0.1)
self.fc_V.bias.data.zero_()
update()
def update(self,transition_dict):
"""
#### Transition Dictionary
- states : ```[BatchSize,nAgents,StateDim]```
- actions : ```[BatchSize,nAgents]```
- rewards : ```[BatchSize,nAgents]```
- next_states : ```[BatchSize,nAgents,StateDim]```
- dones : ```[BatchSize,nAgents]```
- hidden_states : ```[BatchSize,NumLayers,nAgents,HiddenDim]```
- cell_states : ```[BatchSize,NumLayers,nAgents,HiddenDim]```
"""
states = torch.tensor(np.array(transition_dict['states']),dtype=torch.float,requires_grad=True).to(device=self.device)
actions = torch.tensor(np.array(transition_dict['actions']),dtype=torch.int64).squeeze(1).unsqueeze(2).to(device=self.device)
rewards = torch.tensor(np.array(transition_dict['rewards']),dtype=torch.float,requires_grad=True).to(device=self.device)
next_states = torch.tensor(np.array(transition_dict['next_states']),dtype=torch.float,requires_grad=True).squeeze().to(device=self.device)
dones = torch.tensor(np.array(transition_dict['dones']),dtype=torch.float,requires_grad=True).to(device=self.device)
hidden_states = torch.tensor(np.array(transition_dict['hiddens']),dtype=torch.float,requires_grad=True).squeeze().to(device=self.device)
cell_states = torch.tensor(np.array(transition_dict['cells']),dtype=torch.float,requires_grad=True).squeeze().to(device=self.device)
# print('States : {}'.format(states.shape))
# print('Actions : {}'.format(actions.shape))
# print('Rewards : {}'.format(rewards.shape))
# print('NextStates : {}'.format(next_states.shape))
# print('Dones : {}'.format(dones.shape))
# print('HiddenStates : {}'.format(hidden_states.shape))
# print('CellStates : {}'.format(cell_states.shape))
q_values,(next_hiddens,next_cells) = self.q_net(states,hidden_states,cell_states)
q_values = q_values.gather(2,actions).squeeze(2)
mix_q_val = self.mixer(q_values) # [batchsize,1]
temp_q , (hs,cs) = self.q_net(next_states,next_hiddens,next_cells)
max_q_actions = temp_q.max(dim=2)[1].unsqueeze(2)
next_q , (hs,cs) = self.target_q_net(next_states,next_hiddens,next_cells)
next_q_vals = next_q.gather(2,max_q_actions).squeeze(2)
mix_next_q_val = self.mixer(next_q_vals) # [batchsize,1]
mix_reward = self.mixer(rewards) # [batchsize,1]
done = dones.sum(dim=1,keepdim=True) # [batchsize,1]
td_targets = mix_reward + self.gamma * mix_next_q_val * (1 - done)
loss = torch.mean(F.mse_loss(mix_q_val,td_targets))
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
I’ve also tried CUDA_LAUNCH_BLOCKING=1 and didn’t make any change to the TrackBack information.
Additionally, when I run everything on cpu, this wired error disappeared!!! It only happens while using .cuda()
This error doesn’t occur when I run the same agent in another enironment or a different agent with the same environment.
This really confused me and really appreciate if somebody can help me out.