I have trained model on colab (with GPU), now when I am trying to predict on local it is giving me this error. I am able to predict on colab but not on local.
Torch version-
In colab 1.5.1+cu101, and in local 1.5.1 (which is CPU only)
Check prediction notebook on Github- https://gist.github.com/Dipeshpal/3aa188915bc2c95d23c2ebbccb318cc8
import torch
import torch.nn as nn
import torch.optim as optim
import torchtext
from torchtext import data
# from torchtext.datasets import Multi30k
from torchtext.data import Field, BucketIterator
# import matplotlib.pyplot as plt
# import matplotlib.ticker as ticker
import spacy
import numpy as np
import random
import math
import time
import os
SEED = 1234
random.seed(SEED)
np.random.seed(SEED)
torch.manual_seed(SEED)
torch.cuda.manual_seed(SEED)
torch.backends.cudnn.deterministic = True
BASE = "dataset/"
folder_name = input("Enter folder name (Ex: en-es | None for en-de): ")
MY_PATH = f"{BASE}{folder_name}"
if MY_PATH == None:
lang1_name = ".en"
lang2_name = ".de"
else:
lang1_name = input("Enter Lang1 Name (Ex: en): ")
lang1_name = "."+lang1_name
lang2_name = input("Enter Lang2 Name (Ex: es): ")
lang2_name = "."+lang2_name
BATCH_SIZE = int(input("Batch Size: (128 Recommended): "))
N_EPOCHS = int(input("Number of Epochs (50 Recommended): "))
tensor_print = input("Do you want to print the tensor summary (Type yes or No): ")
summary = input("Do you want to print model summary (Type yes or No): ")
model_name = f"models/{lang1_name[1:]}-{lang2_name[1:]}/"+lang1_name[1:]+'-'+lang2_name[1:]
print("Model Name: ", model_name)
# print(f"Language 1: {lang1_name}, Language 2: {lang2_name}")
# https://spacy.io/usage/models#languages
spacy_lang1 = spacy.load(lang1_name[1:])
# if lang2_name != ".hi":
# print(f"Second Language is {lang2_name[1:]}")
# # os.system(f"python -m spacy download {lang2_name[1:]}")
spacy_lang2 = spacy.load(lang2_name[1:])
def tokenize_lang1(text):
return [tok.text for tok in spacy_lang1.tokenizer(text)]
def tokenize_lang2(text):
if lang2_name == ".hi":
return tokenize(text, "hi")
else:
return [tok.text for tok in spacy_lang2.tokenizer(text)]
SRC = Field(tokenize = tokenize_lang1,
init_token = '<sos>',
eos_token = '<eos>',
lower = True,
batch_first = True)
TRG = Field(tokenize = tokenize_lang2,
init_token = '<sos>',
eos_token = '<eos>',
lower = True,
batch_first = True)
import os
import xml.etree.ElementTree as ET
import glob
import io
import codecs
class TranslationDataset(data.Dataset):
@staticmethod
def sort_key(ex):
return data.interleave_keys(len(ex.src), len(ex.trg))
def __init__(self, path, exts, fields, **kwargs):
if not isinstance(fields[0], (tuple, list)):
fields = [('src', fields[0]), ('trg', fields[1])]
src_path, trg_path = tuple(os.path.expanduser(path + x) for x in exts)
examples = []
with io.open(src_path, mode='r', encoding='utf-8') as src_file, \
io.open(trg_path, mode='r', encoding='utf-8') as trg_file:
for src_line, trg_line in zip(src_file, trg_file):
src_line, trg_line = src_line.strip(), trg_line.strip()
if src_line != '' and trg_line != '':
examples.append(data.Example.fromlist(
[src_line, trg_line], fields))
super(TranslationDataset, self).__init__(examples, fields, **kwargs)
@classmethod
def splits(cls, exts, fields, path=None, root='dataset',
train='train', validation='val', test='test', **kwargs):
if path is None or path is "en-de":
path = cls.download(root)
train_data = None if train is None else cls(
os.path.join(path, train), exts, fields, **kwargs)
val_data = None if validation is None else cls(
os.path.join(path, validation), exts, fields, **kwargs)
test_data = None if test is None else cls(
os.path.join(path, test), exts, fields, **kwargs)
return tuple(d for d in (train_data, val_data, test_data)
if d is not None)
class CustomMulti30(TranslationDataset):
urls = ['http://www.quest.dcs.shef.ac.uk/wmt16_files_mmt/training.tar.gz',
'http://www.quest.dcs.shef.ac.uk/wmt16_files_mmt/validation.tar.gz',
'http://www.quest.dcs.shef.ac.uk/'
'wmt17_files_mmt/mmt_task1_test2016.tar.gz']
name = "en-de"
dirname = ''
@classmethod
def splits(cls, exts, fields, root='dataset',
train='train', validation='val', test='test', **kwargs):
if 'path' not in kwargs:
expected_folder = os.path.join(root, cls.name)
path = expected_folder if os.path.exists(expected_folder) else None
else:
path = kwargs['path']
del kwargs['path']
if path == None:
train = 'train'
test = 'test2016'
val = 'val'
exts = ('.en', '.de')
return super(CustomMulti30, cls).splits(
exts, fields, path, root, train, validation, test, **kwargs)
train_data, valid_data, test_data = CustomMulti30.splits(exts = (lang1_name, lang2_name), fields = (SRC, TRG), root='dataset', path=MY_PATH,
train='train', validation='val', test='test')
SRC.build_vocab(train_data, min_freq = 2)
TRG.build_vocab(train_data, min_freq = 2)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # output= cpu
train_iterator, valid_iterator, test_iterator = BucketIterator.splits(
(train_data, valid_data, test_data),
batch_size = BATCH_SIZE,
device = device)
model
class Encoder(nn.Module):
def __init__(self,
input_dim,
hid_dim,
n_layers,
n_heads,
pf_dim,
dropout,
device,
max_length = 100):
super().__init__()
self.device = device
self.tok_embedding = nn.Embedding(input_dim, hid_dim)
self.pos_embedding = nn.Embedding(max_length, hid_dim)
self.layers = nn.ModuleList([EncoderLayer(hid_dim,
n_heads,
pf_dim,
dropout,
device)
for _ in range(n_layers)])
self.dropout = nn.Dropout(dropout)
self.scale = torch.sqrt(torch.FloatTensor([hid_dim])).to(device)
def forward(self, src, src_mask):
#src = [batch size, src len]
#src_mask = [batch size, src len]
batch_size = src.shape[0]
src_len = src.shape[1]
pos = torch.arange(0, src_len).unsqueeze(0).repeat(batch_size, 1).to(self.device)
#pos = [batch size, src len]
src = self.dropout((self.tok_embedding(src) * self.scale) + self.pos_embedding(pos))
#src = [batch size, src len, hid dim]
for layer in self.layers:
src = layer(src, src_mask)
#src = [batch size, src len, hid dim]
return src
class EncoderLayer(nn.Module):
def __init__(self,
hid_dim,
n_heads,
pf_dim,
dropout,
device):
super().__init__()
self.self_attn_layer_norm = nn.LayerNorm(hid_dim)
self.ff_layer_norm = nn.LayerNorm(hid_dim)
self.self_attention = MultiHeadAttentionLayer(hid_dim, n_heads, dropout, device)
self.positionwise_feedforward = PositionwiseFeedforwardLayer(hid_dim,
pf_dim,
dropout)
self.dropout = nn.Dropout(dropout)
def forward(self, src, src_mask):
#src = [batch size, src len, hid dim]
#src_mask = [batch size, src len]
#self attention
_src, _ = self.self_attention(src, src, src, src_mask)
#dropout, residual connection and layer norm
src = self.self_attn_layer_norm(src + self.dropout(_src))
#src = [batch size, src len, hid dim]
#positionwise feedforward
_src = self.positionwise_feedforward(src)
#dropout, residual and layer norm
src = self.ff_layer_norm(src + self.dropout(_src))
#src = [batch size, src len, hid dim]
return src
class MultiHeadAttentionLayer(nn.Module):
def __init__(self, hid_dim, n_heads, dropout, device):
super().__init__()
assert hid_dim % n_heads == 0
self.hid_dim = hid_dim
self.n_heads = n_heads
self.head_dim = hid_dim // n_heads
self.fc_q = nn.Linear(hid_dim, hid_dim)
self.fc_k = nn.Linear(hid_dim, hid_dim)
self.fc_v = nn.Linear(hid_dim, hid_dim)
self.fc_o = nn.Linear(hid_dim, hid_dim)
self.dropout = nn.Dropout(dropout)
self.scale = torch.sqrt(torch.FloatTensor([self.head_dim])).to(device)
def forward(self, query, key, value, mask = None):
batch_size = query.shape[0]
#query = [batch size, query len, hid dim]
#key = [batch size, key len, hid dim]
#value = [batch size, value len, hid dim]
Q = self.fc_q(query)
K = self.fc_k(key)
V = self.fc_v(value)
#Q = [batch size, query len, hid dim]
#K = [batch size, key len, hid dim]
#V = [batch size, value len, hid dim]
Q = Q.view(batch_size, -1, self.n_heads, self.head_dim).permute(0, 2, 1, 3)
K = K.view(batch_size, -1, self.n_heads, self.head_dim).permute(0, 2, 1, 3)
V = V.view(batch_size, -1, self.n_heads, self.head_dim).permute(0, 2, 1, 3)
#Q = [batch size, n heads, query len, head dim]
#K = [batch size, n heads, key len, head dim]
#V = [batch size, n heads, value len, head dim]
energy = torch.matmul(Q, K.permute(0, 1, 3, 2)) / self.scale
#energy = [batch size, n heads, query len, key len]
if mask is not None:
energy = energy.masked_fill(mask == 0, -1e10)
attention = torch.softmax(energy, dim = -1)
#attention = [batch size, n heads, query len, key len]
x = torch.matmul(self.dropout(attention), V)
#x = [batch size, n heads, query len, head dim]
x = x.permute(0, 2, 1, 3).contiguous()
#x = [batch size, query len, n heads, head dim]
x = x.view(batch_size, -1, self.hid_dim)
#x = [batch size, query len, hid dim]
x = self.fc_o(x)
#x = [batch size, query len, hid dim]
return x, attention
class PositionwiseFeedforwardLayer(nn.Module):
def __init__(self, hid_dim, pf_dim, dropout):
super().__init__()
self.fc_1 = nn.Linear(hid_dim, pf_dim)
self.fc_2 = nn.Linear(pf_dim, hid_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
#x = [batch size, seq len, hid dim]
x = self.dropout(torch.relu(self.fc_1(x)))
#x = [batch size, seq len, pf dim]
x = self.fc_2(x)
#x = [batch size, seq len, hid dim]
return x
class Decoder(nn.Module):
def __init__(self,
output_dim,
hid_dim,
n_layers,
n_heads,
pf_dim,
dropout,
device,
max_length = 100):
super().__init__()
self.device = device
self.tok_embedding = nn.Embedding(output_dim, hid_dim)
self.pos_embedding = nn.Embedding(max_length, hid_dim)
self.layers = nn.ModuleList([DecoderLayer(hid_dim,
n_heads,
pf_dim,
dropout,
device)
for _ in range(n_layers)])
self.fc_out = nn.Linear(hid_dim, output_dim)
self.dropout = nn.Dropout(dropout)
self.scale = torch.sqrt(torch.FloatTensor([hid_dim])).to(device)
def forward(self, trg, enc_src, trg_mask, src_mask):
#trg = [batch size, trg len]
#enc_src = [batch size, src len, hid dim]
#trg_mask = [batch size, trg len]
#src_mask = [batch size, src len]
batch_size = trg.shape[0]
trg_len = trg.shape[1]
pos = torch.arange(0, trg_len).unsqueeze(0).repeat(batch_size, 1).to(self.device)
#pos = [batch size, trg len]
trg = self.dropout((self.tok_embedding(trg) * self.scale) + self.pos_embedding(pos))
#trg = [batch size, trg len, hid dim]
for layer in self.layers:
trg, attention = layer(trg, enc_src, trg_mask, src_mask)
#trg = [batch size, trg len, hid dim]
#attention = [batch size, n heads, trg len, src len]
output = self.fc_out(trg)
#output = [batch size, trg len, output dim]
return output, attention
class DecoderLayer(nn.Module):
def __init__(self,
hid_dim,
n_heads,
pf_dim,
dropout,
device):
super().__init__()
self.self_attn_layer_norm = nn.LayerNorm(hid_dim)
self.enc_attn_layer_norm = nn.LayerNorm(hid_dim)
self.ff_layer_norm = nn.LayerNorm(hid_dim)
self.self_attention = MultiHeadAttentionLayer(hid_dim, n_heads, dropout, device)
self.encoder_attention = MultiHeadAttentionLayer(hid_dim, n_heads, dropout, device)
self.positionwise_feedforward = PositionwiseFeedforwardLayer(hid_dim,
pf_dim,
dropout)
self.dropout = nn.Dropout(dropout)
def forward(self, trg, enc_src, trg_mask, src_mask):
#trg = [batch size, trg len, hid dim]
#enc_src = [batch size, src len, hid dim]
#trg_mask = [batch size, trg len]
#src_mask = [batch size, src len]
#self attention
_trg, _ = self.self_attention(trg, trg, trg, trg_mask)
#dropout, residual connection and layer norm
trg = self.self_attn_layer_norm(trg + self.dropout(_trg))
#trg = [batch size, trg len, hid dim]
#encoder attention
_trg, attention = self.encoder_attention(trg, enc_src, enc_src, src_mask)
#dropout, residual connection and layer norm
trg = self.enc_attn_layer_norm(trg + self.dropout(_trg))
#trg = [batch size, trg len, hid dim]
#positionwise feedforward
_trg = self.positionwise_feedforward(trg)
#dropout, residual and layer norm
trg = self.ff_layer_norm(trg + self.dropout(_trg))
#trg = [batch size, trg len, hid dim]
#attention = [batch size, n heads, trg len, src len]
return trg, attention
class Seq2Seq(nn.Module):
def __init__(self,
encoder,
decoder,
src_pad_idx,
trg_pad_idx,
device):
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.src_pad_idx = src_pad_idx
self.trg_pad_idx = trg_pad_idx
self.device = device
def make_src_mask(self, src):
#src = [batch size, src len]
src_mask = (src != self.src_pad_idx).unsqueeze(1).unsqueeze(2)
#src_mask = [batch size, 1, 1, src len]
return src_mask
def make_trg_mask(self, trg):
#trg = [batch size, trg len]
trg_pad_mask = (trg != self.trg_pad_idx).unsqueeze(1).unsqueeze(2)
#trg_pad_mask = [batch size, 1, 1, trg len]
trg_len = trg.shape[1]
trg_sub_mask = torch.tril(torch.ones((trg_len, trg_len), device = self.device)).bool()
#trg_sub_mask = [trg len, trg len]
trg_mask = trg_pad_mask & trg_sub_mask
#trg_mask = [batch size, 1, trg len, trg len]
return trg_mask
def forward(self, src, trg):
#src = [batch size, src len]
#trg = [batch size, trg len]
src_mask = self.make_src_mask(src)
trg_mask = self.make_trg_mask(trg)
#src_mask = [batch size, 1, 1, src len]
#trg_mask = [batch size, 1, trg len, trg len]
enc_src = self.encoder(src, src_mask)
#enc_src = [batch size, src len, hid dim]
output, attention = self.decoder(trg, enc_src, trg_mask, src_mask)
#output = [batch size, trg len, output dim]
#attention = [batch size, n heads, trg len, src len]
return output, attention
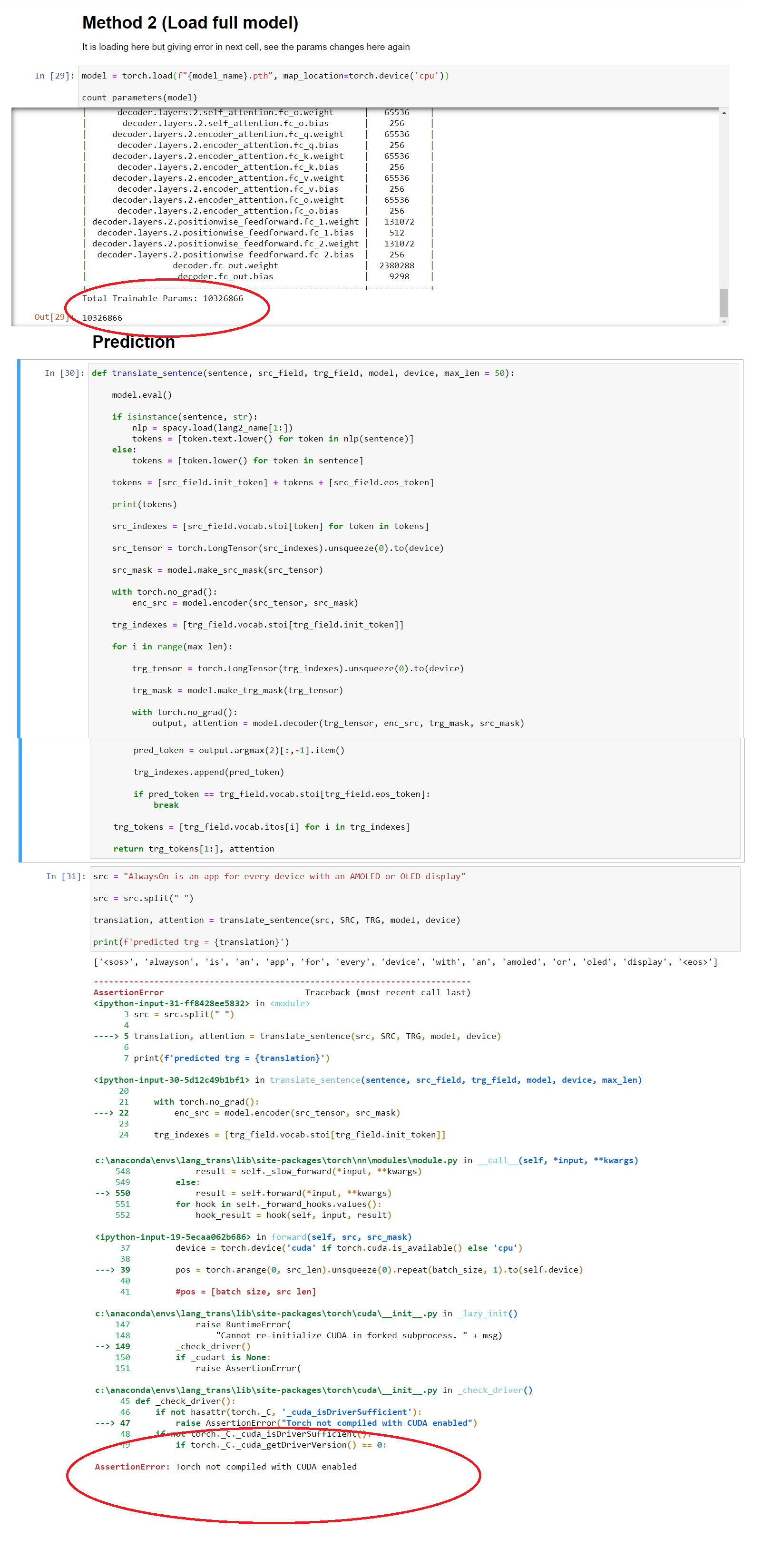
model = torch.load(f"{model_name}.pth", map_location=torch.device('cpu'))
prediction
def translate_sentence(sentence, src_field, trg_field, model, device, max_len = 50):
model.eval()
if isinstance(sentence, str):
nlp = spacy.load(lang2_name[1:])
tokens = [token.text.lower() for token in nlp(sentence)]
else:
tokens = [token.lower() for token in sentence]
tokens = [src_field.init_token] + tokens + [src_field.eos_token]
src_indexes = [src_field.vocab.stoi[token] for token in tokens]
src_tensor = torch.LongTensor(src_indexes).unsqueeze(0)
src_mask = model.make_src_mask(src_tensor)
with torch.no_grad():
enc_src = model.encoder(src_tensor, src_mask)
trg_indexes = [trg_field.vocab.stoi[trg_field.init_token]]
for i in range(max_len):
trg_tensor = torch.LongTensor(trg_indexes).unsqueeze(0)
trg_mask = model.make_trg_mask(trg_tensor)
with torch.no_grad():
output, attention = model.decoder(trg_tensor, enc_src, trg_mask, src_mask)
pred_token = output.argmax(2)[:,-1].item()
trg_indexes.append(pred_token)
if pred_token == trg_field.vocab.stoi[trg_field.eos_token]:
break
trg_tokens = [trg_field.vocab.itos[i] for i in trg_indexes]
return trg_tokens[1:], attention
src = "AlwaysOn is an app for every device with an AMOLED or OLED display"
translation, attention = translate_sentence(src, SRC, TRG, model, device)
print(f'predicted trg = {translation}')
It is throwing an error-
---------------------------------------------------------------------------
AssertionError Traceback (most recent call last)
<ipython-input-48-cbfed1f58bee> in <module>
1 src = "AlwaysOn is an app for every device with an AMOLED or OLED display"
2
----> 3 translation, attention = translate_sentence(src, SRC, TRG, model, device)
4
5 print(f'predicted trg = {translation}')
<ipython-input-47-8a2c8a0fc6e3> in translate_sentence(sentence, src_field, trg_field, model, device, max_len)
18
19 with torch.no_grad():
---> 20 enc_src = model.encoder(src_tensor, src_mask)
21
22 trg_indexes = [trg_field.vocab.stoi[trg_field.init_token]]
c:\anaconda\envs\lang_tr_3\lib\site-packages\torch\nn\modules\module.py in __call__(self, *input, **kwargs)
548 result = self._slow_forward(*input, **kwargs)
549 else:
--> 550 result = self.forward(*input, **kwargs)
551 for hook in self._forward_hooks.values():
552 hook_result = hook(self, input, result)
<ipython-input-42-42e4e1534246> in forward(self, src, src_mask)
35 src_len = src.shape[1]
36
---> 37 pos = torch.arange(0, src_len).unsqueeze(0).repeat(batch_size, 1).to(self.device)
38
39 #pos = [batch size, src len]
c:\anaconda\envs\lang_tr_3\lib\site-packages\torch\cuda\__init__.py in _lazy_init()
147 raise RuntimeError(
148 "Cannot re-initialize CUDA in forked subprocess. " + msg)
--> 149 _check_driver()
150 if _cudart is None:
151 raise AssertionError(
c:\anaconda\envs\lang_tr_3\lib\site-packages\torch\cuda\__init__.py in _check_driver()
45 def _check_driver():
46 if not hasattr(torch._C, '_cuda_isDriverSufficient'):
---> 47 raise AssertionError("Torch not compiled with CUDA enabled")
48 if not torch._C._cuda_isDriverSufficient():
49 if torch._C._cuda_getDriverVersion() == 0:
AssertionError: Torch not compiled with CUDA enabled