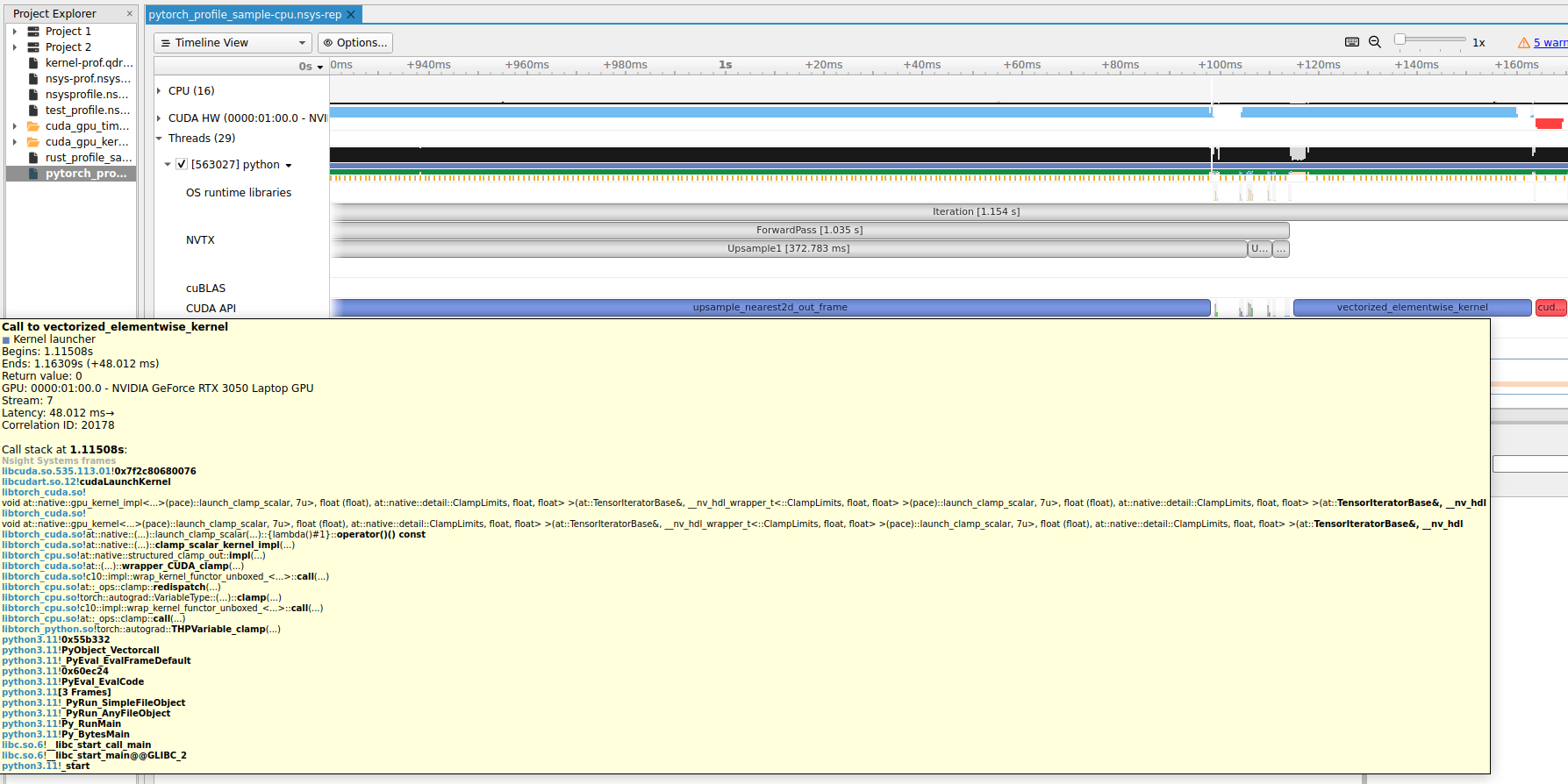
I’m profiling pytorch code using NVIDIA nsys and noticed calls to kernels such as at::native::::CatArrayBatchedCopy and at::native::elementwise_kernel. I can see the implementations of these kernels here and here.
However, I can’t seem to find where these kernels are actually called when searching the repo – searching for these identifiers only results in the implementation files.
I’d like the trace the chain of calls leading to these kernel launches from higher-level operators (e.g., Conv2d), and more generally, understand the internal plumbing of pytorch in greater detail.
Would greatly appreciate if anybody could explain how Aten native operators are connected to higher-level functions and eventually connected to Python!
at::native kernels are dynamically registered to the pytorch dispatcher through code-generated files (which has been a very useful abstraction, but can make grepping the codebase for them difficult).