I have observed in the implementations by Pytorch and others, encoder outputs are used instead encoder hidden states to calculate attention weights. Does the make no difference? One reason that I’ve observed is that using LSTM without manually looping through the sequence results in the entire sequence at the output but only final hidden state. Are there other reasons for using encoder outputs instead of encoder hidden states ?
The encoder outputs ARE the hidden states at each time step. Look at the following sketch of an LSTM cell:
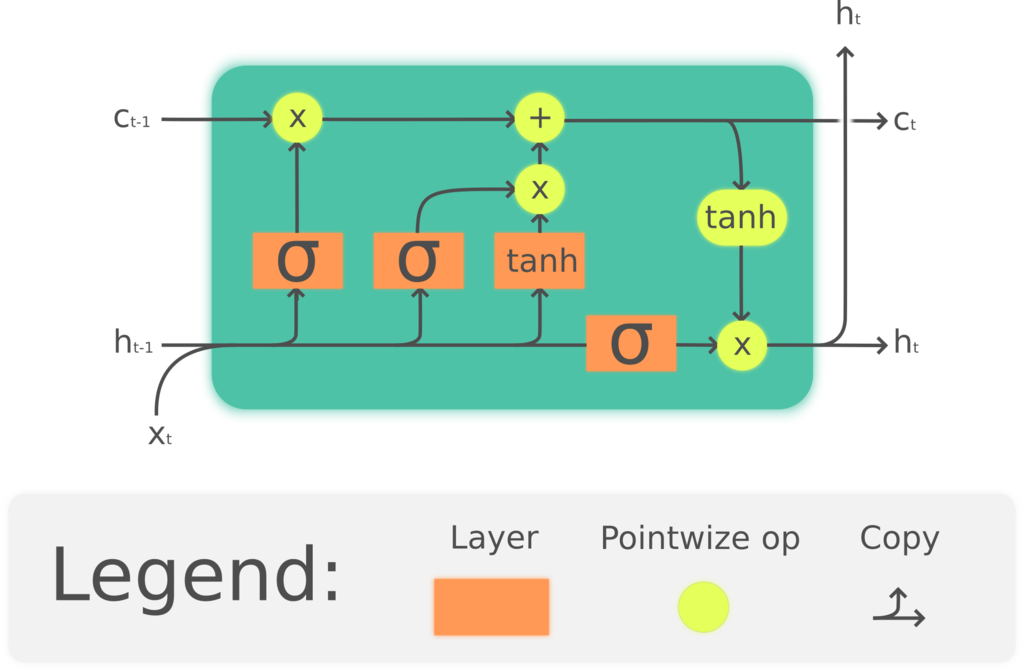
There is not “extra” output, it’s just the current hidden state h_t. For example, if you define an lstm with num_layers=0 and batch_first=False, and given, say,
output, (h, c) = lstm(inputs, hidden)
then output[-1] = h_n, simply meaning that you can get the final hidden state directly from h or as the last hidden state from output. If you have more layers (num_layers>1), things are a bit different: output will contain only the hidden states for each time stamp after the last layer, while h will contain the last hidden states for each layer.
1 Like
Thanks, I totally missed out on this. Surprisingly, I have seen this question asked by others and people are suggesting to manually loop over sequence length to capture the hidden states.