I recently started reading up on attention in the context of computer vision. In my research, I found a number of ways attention is applied for various CV tasks. However, it is still unclear to me as to what’s really happening.
When I say attention, I mean a mechanism that will focus on the important features of an image, similar to how it’s done in NLP (machine translation).
I’m looking for resources (blogs/gifs/videos) with PyTorch code that explains how to implement attention for, let’s say, a simple image classification task.
Alternatively, It would be great if you write a small implementation of only the attention mechanism in the following way -
Assume a tensor of size (h,w,c)
input tensor => attention => output
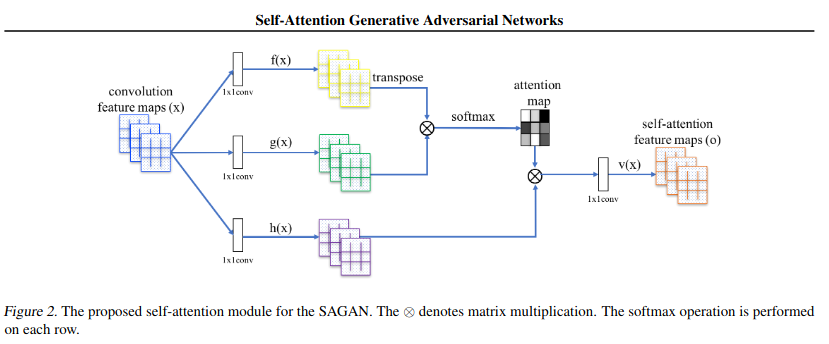
One example is the self-attention from the SAGAN paper -
Attentions are used to focus on specific features rather than giving importance to all the features. The convolutional network gives out large number of features and some of those features are not so important information but they also consume computation time when passed forward. Here in this case we use attention networks to assign more importance to useful features in which we are interested.
import torch.nn as nn
class SelfAttention(nn.Module):
""" Self attention Layer"""
def __init__(self,in_dim,activation):
super(SelfAttention,self).__init__()
self.chanel_in = in_dim
self.activation = activation
self.query_conv = nn.Conv2d(in_channels = in_dim , out_channels = in_dim//8 , kernel_size= 1)
self.key_conv = nn.Conv2d(in_channels = in_dim , out_channels = in_dim//8 , kernel_size= 1)
self.value_conv = nn.Conv2d(in_channels = in_dim , out_channels = in_dim , kernel_size= 1)
self.gamma = nn.Parameter(torch.zeros(1))
self.softmax = nn.Softmax(dim=-1) #
def forward(self,x):
"""
inputs :
x : input feature maps( B X C X W X H)
returns :
out : self attention value + input feature
attention: B X N X N (N is Width*Height)
"""
m_batchsize,C,width ,height = x.size()
proj_query = self.query_conv(x).view(m_batchsize,-1,width*height).permute(0,2,1) # B X CX(N)
proj_key = self.key_conv(x).view(m_batchsize,-1,width*height) # B X C x (*W*H)
energy = torch.bmm(proj_query,proj_key) # transpose check
attention = self.softmax(energy) # BX (N) X (N)
proj_value = self.value_conv(x).view(m_batchsize,-1,width*height) # B X C X N
out = torch.bmm(proj_value,attention.permute(0,2,1) )
out = out.view(m_batchsize,C,width,height)
out = self.gamma*out + x
return out,attention
Hi, @AdilZouitine I am using self-attention in a personal project, which has the exact same implementation mentioned by you. However, if feature maps sizes get larger even up to (B,128,256,256), the program runs out of memory on my GPU of 12 GB memory. Is there any workaround this apart from going for a bigger GPU? The network is not even able to run one forward pass.
Hi @sharad , In the paper I posted, the authors use self-attention after processing the image with a succession of convolution layers.
This means that at the input of the self-attention layer the size of the features map is already reduced and therefore takes less RAM memory.
am tring to use the same self-attention implementation on colab but it runs out of memory , how can i modify it so it can run correctly on colab CUDA GPU ?