Hi guys, I have trouble with the following. I have images (3-channel) and corresponding masks (1-channel) which contains areas/pixels where I would like my classifier to focus on. The mask is passed through a simple CNN. It’s only purpose is to abstractify the mask (I do not intend to train it) in the same size as the corresponding classification CNN. The mask features need to be added to each image feature map. I made a simple schematic which hopefully makes this explanation clear.
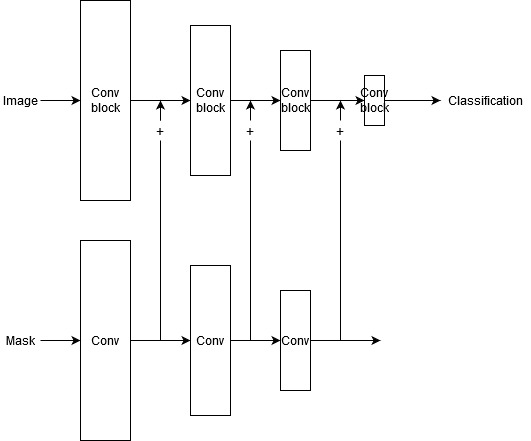
In my attempt I try to avoid explicitly stating all additions manually because I want to be able to dynamically specify the amount of layers. A mwp can be found below, however, I encounter the issue that I am only able to add attention to the first conv block. I am running out of CUDA memory once I try to add attention to the second and last/classification block (see commented out sections). I think that the reason for this is that I am unintentionally also training the attention blocks. Is there a better and more efficient method of achieving my goal? I have tried to declare the “attentionbranch” in a seperate class, however I am not sure how to add the intermediate mask features to the image features in a single forward pass.
Any pointers are appreciated! Thanks!
import torch
import torch.nn as nn
class BasicDiscriminator(nn.Module):
def __init__(self, opt):
super(BasicDiscriminator, self).__init__()
isize = opt.isize
nz = opt.nz
nc = opt.nc
ngf = opt.ngf
ndf = opt.ndf
n_extra_layers = opt.extralayers
feat1 = nn.Sequential()
feat2 = nn.Sequential()
clas = nn.Sequential()
att1 = nn.Sequential()
att2 = nn.Sequential()
clas2 = nn.Sequential()
# input is nc x isize x isize
feat1.add_module('initial-conv-{0}-{1}'.format(nc, ndf), nn.Conv2d(nc, ndf, 4, 2, 1, bias=False))
feat1.add_module('initial-relu-{0}'.format(ndf), nn.LeakyReLU(0.2, inplace=True))
# init Attention model
att1.add_module('attention-conv2d-{0}-{1}'.format(1, ndf), nn.Conv2d(1, ndf, 4, 2, 1, bias=True))
csize, cndf = isize / 2, ndf
# Extra layers
for t in range(n_extra_layers):
feat2.add_module('extra-layers-{0}-{1}-conv'.format(t, cndf),
nn.Conv2d(cndf, cndf, 3, 1, 1, bias=False))
feat2.add_module('extra-layers-{0}-{1}-batchnorm'.format(t, cndf),
nn.BatchNorm2d(cndf))
feat2.add_module('extra-layers-{0}-{1}-relu'.format(t, cndf),
nn.LeakyReLU(0.2, inplace=True))
att2.add_module('attention_extra_layers-conv2d-{0}-{1}'.format(t, ndf),
nn.Conv2d(cndf, cndf, 3, 1, 1, bias=True))
while csize > 4:
in_feat = cndf
out_feat = cndf * 2
feat2.add_module('pyramid-{0}-{1}-conv'.format(in_feat, out_feat),
nn.Conv2d(in_feat, out_feat, 4, 2, 1, bias=False))
feat2.add_module('pyramid-{0}-batchnorm'.format(out_feat),
nn.BatchNorm2d(out_feat))
feat2.add_module('pyramid-{0}-relu'.format(out_feat),
nn.LeakyReLU(0.2, inplace=True))
att2.add_module('attention-pyramid-conv2d-{0}-{1}'.format(1, out_feat),
nn.Conv2d(in_feat, out_feat, stride=2, kernel_size=3, padding=1, bias=True))
cndf = cndf * 2
csize = csize / 2
feat2.add_module('final-{0}-{1}-conv'.format(cndf, 1),
nn.Conv2d(cndf, nz, 4, 1, 0, bias=False))
att2.add_module('attention-final-{0}-{1}-conv'.format(cndf, 1),
nn.Conv2d(cndf, nz, 4, 1, 0, bias=True))
clas.add_module('classifier', nn.Conv2d(nz, 1, 3, 1, 1, bias=False))
clas.add_module('Sigmoid', nn.Sigmoid())
clas2.add_module('attention-classifier', nn.Conv2d(nz, 1, 3, 1, 1, bias=False))
self.feat1 = feat1
self.feat2 = feat2
self.clas = clas
self.att1 = att1
self.att2 = att2
self.clas2 = clas2
def forward(self, input, mask):
# Add attention to initial conv block
feat1 = input
for layer in self.feat1:
# add attention to conv layer only
if isinstance(layer, nn.Conv2d):
feat1 = layer(feat1)
attention1 = self.att1(mask) # extract features of att block
feat1 = feat1 + attention1
else:
feat1 = layer(feat1)
# # add attention to second conv block
# feat2 = feat1
# attention2 = attention1
# counter = 0
# for layer in self.feat2:
# if isinstance(layer, nn.Conv2d):
# feat2 = layer(feat2)
# attention2 = self.att2[counter](attention2)
# feat2 = feat2 + attention2
# counter += 1
# else:
# feat2 = layer(feat2)
# # add attention to classifying block
# clas = feat2
# for layer in self.clas:
# if isinstance(layer, nn.Conv2d):
# clas = layer(clas)
# clas2 = self.clas2(attention2)
# clas = clas + clas2
# else:
# clas = layer(clas)
feat2 = self.feat2(feat1)
clas = self.clas(feat2)
clas = clas.view(-1, 1).squeeze(1)
return clas, feat2