Hi, I am implementing a paper Show, Attend and Interact: Human-Robot Interaction (https://arxiv.org/pdf/1702.08626.pdf) in pytorch. I have successfully implemented the following architecture and now I also have an annotation vector z from the attention module (G).
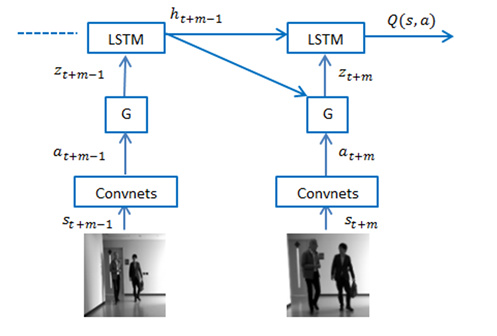
My question is, how to use the annotation vector to put attention mask on the input image to indicate attention region.
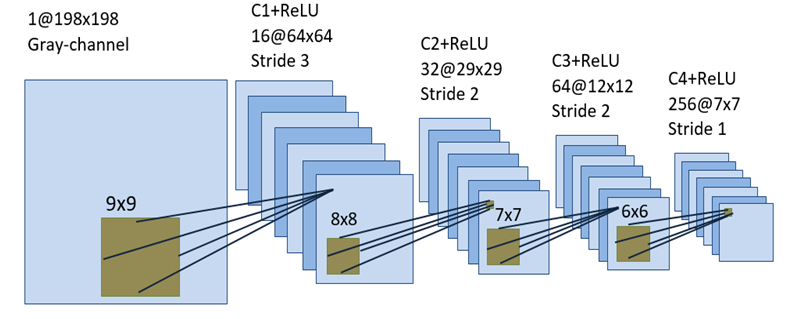
My Convnets takes an image of 198x198 to transform it to 256 feature maps (a) of size 7x7 as follow:
My attention module takes input in the form 49X256=7x7x256 and outputs an annotation vector z as follow:
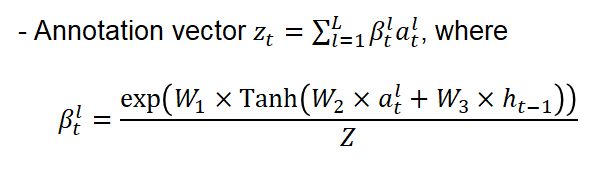
In original torch/lua, I used to display attention mask using the nn.subsampling method as shown below:
local upsample = nn.Sequential()
upsample:add(nn.SpatialSubSampling(1,9,9,3,3))
upsample:add(nn.SpatialSubSampling(1,8,8,2,2))
upsample:add(nn.SpatialSubSampling(1,7,7,2,2))
upsample:add(nn.SpatialSubSampling(1,6,6,1,1))
upsample:float()
local w, dw = upsample:getParameters()
w:fill(0.25)
dw:zero()
local empty = torch.zeros(1,198,198):float()
upsample:forward(empty)
local attention, q = self:predict(state[m])
attention = upsample:updateGradInput(empty,attention:float())
attention = image.scale(attention, 198, 198, ‘bilinear’)
Please tell me the way to indcate attention mask using pytorch as I am not able to find any subsampling function.