Hi all,
I’m trying to do a seq2seq model on phonemes of lyrics. My attention model, which is based on the model found in the seq2seq tutorial, often attends WAY beyond the length of the sequence. I understand that we need to set a maximum length to define the set length of the attention layer, but based on my understanding, it shouldn’t look at those extra parts of the layer when looking at short sentences. See the following pictures of some outputs:
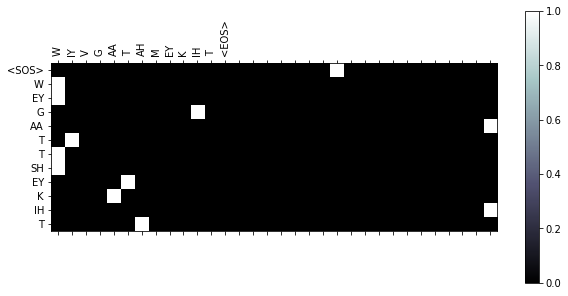
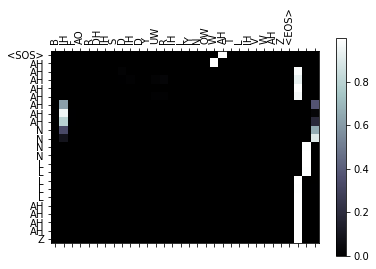
Here’s the network code for the encoder and decoder. Lemme know if you see anyway to help me!
class EncoderRNN(nn.Module):
def __init__(self, input_size, hidden_size):
super(EncoderRNN, self).__init__()
self.hidden_size = hidden_size
# add if w/ cuda
self.embedding = nn.Embedding(input_size, hidden_size).cuda()
self.gru = nn.GRU(hidden_size, hidden_size).cuda()
def forward(self, input, hidden):
embedded = self.embedding(input).view(1, 1, -1)
output = embedded
output, hidden = self.gru(output, hidden)
return output, hidden
def initHidden(self):
result = Variable(torch.zeros(1, 1, self.hidden_size))
if use_cuda:
return result.cuda()
else:
return result
class AttnDecoderRNN(nn.Module):
def __init__(self, hidden_size, output_size, dropout_p=0.1, max_length=MAX_LENGTH+2):
super(AttnDecoderRNN, self).__init__()
self.hidden_size = hidden_size
self.output_size = output_size
self.dropout_p = dropout_p
self.max_length = max_length
self.embedding = nn.Embedding(self.output_size, self.hidden_size).cuda()
self.attn = nn.Linear(self.hidden_size * 2, self.max_length).cuda()
self.attn_combine = nn.Linear(self.hidden_size * 2, self.hidden_size).cuda()
self.dropout = nn.Dropout(self.dropout_p).cuda()
self.gru = nn.GRU(self.hidden_size, self.hidden_size).cuda()
self.out = nn.Linear(self.hidden_size, self.output_size).cuda()
def forward(self, input, hidden, encoder_outputs):
embedded = self.embedding(input).view(1, 1, -1)
embedded = self.dropout(embedded)
attn_weights = F.softmax(
self.attn(torch.cat((embedded[0], hidden[0]), 1)), dim=1)
attn_applied = torch.bmm(attn_weights.unsqueeze(0),
encoder_outputs.unsqueeze(0))
output = torch.cat((embedded[0], attn_applied[0]), 1)
output = self.attn_combine(output).unsqueeze(0)
output = F.relu(output)
output, hidden = self.gru(output, hidden)
output = F.log_softmax(self.out(output[0]), dim=1)
return output, hidden, attn_weights
def initHidden(self):
result = Variable(torch.zeros(1, 1, self.hidden_size))
if use_cuda:
return result.cuda()
else:
return result