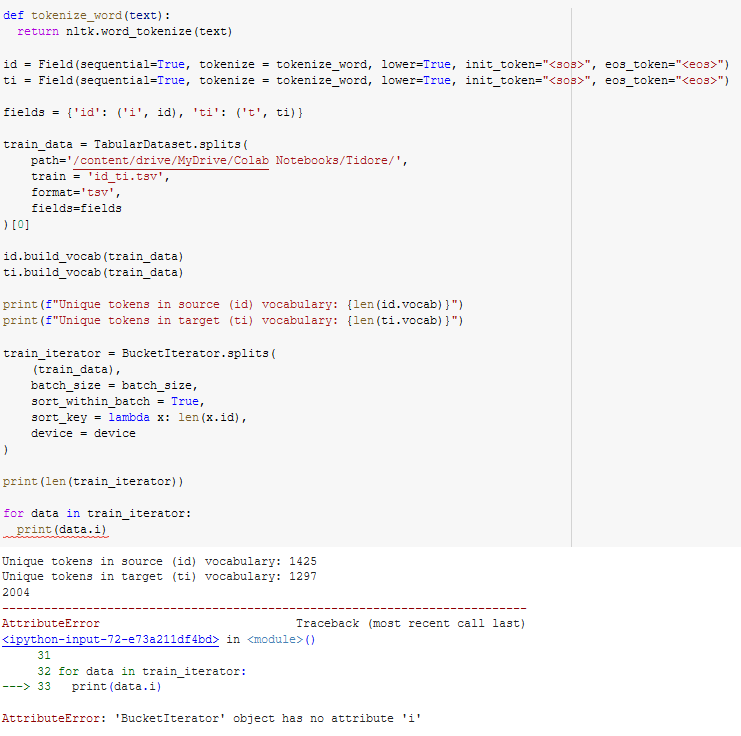
I’m doing seq2seq machine translation on my own dataset. I have preproceed my dataset using this code. The problem comes when i tried to split train_data using BucketIterator.split()
I am very confuse, because i don’t know what key i should use for train iterator. Thank you for your help
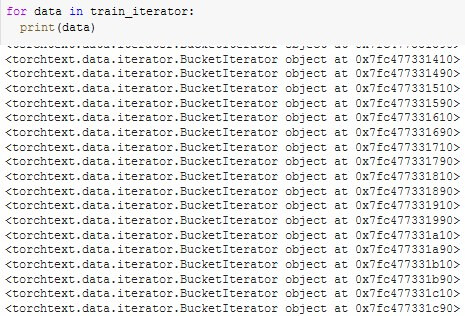
Try changing print(data.i) to print(data). That should give you some ideas on the names involved.
print(data.i)
print(data)
@gphilip Thank you for your response. I have tried, but it makes me more confuse
Asking Google about “torchtext BucketIterator” threw up this tutorial. You may find it useful.