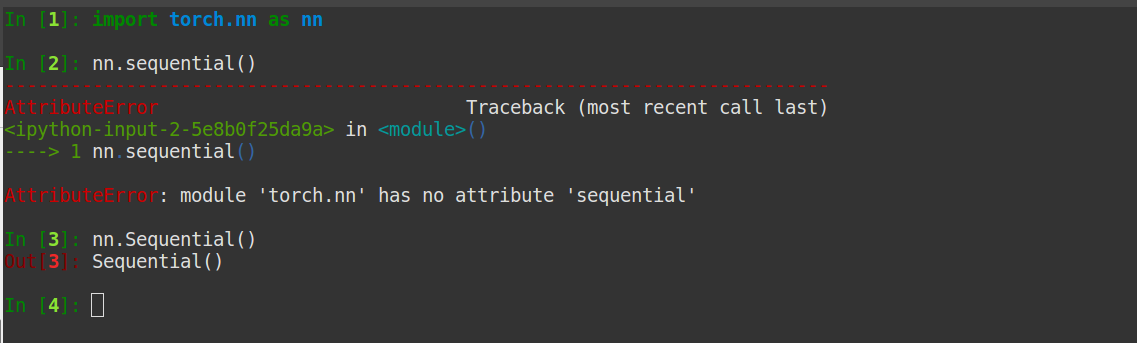
I am trying to implement the Unet model for semantic segmentation based on this paper. Since Conv and Relu need to use many times in this model, I defined a different class for these and called it ConvRelu, and I used sequential as well. I am getting an error AttributeError: module 'torch.nn' has no attribute 'sequential' not sure where I am doing wrong. Thank you in advance.
class ConvRelu(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, padding, stride):
super(ConvRelu, self).__init__()
self.fc1 = nn.Sequential(nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size,
padding=padding, stride=stride), nn.ReLU())
def forward(self, x):
x = self.fc1(x)
return x
class UNet(nn.Module):
def __init__(self):
super(UNet, self).__init__()
#channels, height, width = in_shape
self.down1 = nn.Sequential(
ConvRelu(1, 64, kernel_size=(3, 3), stride=1, padding=0),
ConvRelu(64, 64, kernel_size=(3, 3), stride=1, padding=0)
)
self.maxPool1 = nn.MaxPool2d(kernel_size=(2, 2), stride=2)
self.down2 = nn.sequential(
ConvRelu(64, 128, kernel_size=(3, 3), stride=1, padding=0),
ConvRelu(128, 128, kernel_size=(3, 3), stride=1, padding=0)
)
self.maxPool2 = nn.MaxPool2d(kernel_size=(2, 2), stride=2)
self.down3 = nn.Sequential(
ConvRelu(128, 256, kernel_size=(3, 3), stride=1, padding=0),
ConvRelu(256, 256, kernel_size=(3, 3), stride=1, padding=0)
)
self.maxPool3 = nn.MaxPool2d(kernel_size=(2, 2), stride=2)
self.down4 = nn.Sequential(
ConvRelu(256, 512, kernel_size=(3, 3), stride=1, padding=0),
ConvRelu(512, 512, kernel_size=(3, 3), stride=1, padding=0)
)
self.maxPool4 = nn.MaxPool2d(kernel_size=(2, 2), stride=2)
self.center = nn.Sequential(
ConvRelu(512, 1024, kernel_size=(3, 3), stride=1, padding=0),
ConvRelu(1024, 1024, kernel_size=(3, 3), stride=1, padding=0)
)
self.upSample1 = nn.ConvTranspose2d(1024, 1024, 2, stride=2)
self.up1 = nn.Sequential(
ConvRelu(1024, 512, kernel_size=(2, 2), stride=1, padding=0),
ConvRelu(512, 512, kernel_size=(2, 2), stride=1, padding=0)
)
self.upSample2 = nn.ConvTranspose2d(512, 512, 2, stride=2)
self.up2 = nn.Sequential(
ConvRelu(512, 256, kernel_size=(2, 2), stride=1, padding=0),
ConvRelu(256, 256, kernel_size=(2, 2), stride=1, padding=0)
)
self.upSample3 = nn.ConvTranspose2d(256, 256, 2, stride=2)
self.up3 = nn.Sequential(
ConvRelu(256, 128, kernel_size=(2, 2), stride=1, padding=0),
ConvRelu(128, 128, kernel_size=(2, 2), stride=1, padding=0)
)
self.upSample4 = nn.ConvTranspose2d(128, 128, 2, stride=2)
self.up4 = nn.Sequential(
ConvRelu(128, 64, kernel_size=(2, 2), stride=1, padding=0),
)
# 1x1 convolution at the last layer
self.output_seg_map = nn.Conv2d(64, 2, kernel_size=(1, 1), padding=0, stride=1)
def crop_concat(self, upsampled, bypass, crop=False):
if crop:
c = (bypass.size()[2] - upsampled.size()[2]) // 2
# -c is amount of pad which will add on each side for all dimension
bypass = F.pad(bypass, (-c, -c, -c, -c)) # (padLeft, padRight, padTop, padBottom)
return torch.cat((upsampled, bypass), 1)
def forward(self, x):
x = self.down1(x)
out_down1 = x
x = self.down2(x)
out_down2 = x
x = self.maxPool2(x)
x = self.down3(x)
out_down3 = x
x = self.maxPool3(x)
x = self.down4(x)
out_down4 = x
x = self.maxPool4(x)
x = self.center(x)
x = self.upSample1(x)
x = self.up1(x)
self.crop_concat(x, out_down4)
x = self.upSample2(x)
x = self.up2(x)
self.crop_concat(x, out_down3)
x = self.upSample3(x)
x = self.up3(x)
self.crop_concat(x, out_down2)
x = self.upSample4(x)
x = self.up4(x)
self.crop_concat(x, out_down1)
out = self.output_seg_map(x)
return F.log_softmax(self.output_seg_map(out)) # applies log-softmax on last layer
net = UNet()
net = net.to(device)```