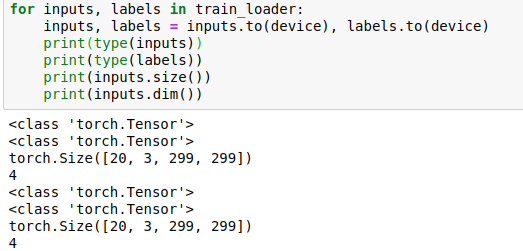
I’m trying to classify my images using transfer learning with inception_v3 and having an error
RuntimeError: cuDNN error: CUDNN_STATUS_BAD_PARAM
What would be the reason of this error ?
My transform
transform = transforms.Compose([ transforms.CenterCrop(1000), transforms.Resize((299,299)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
My model implementation
# Use GPU if it's available
from collections import OrderedDict
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = models.inception_v3(pretrained=True)
# Freeze parameters so we don't backprop through them
for param in model.parameters():
param.requires_grad = False
classifier = nn.Sequential(OrderedDict([
('fc1', nn.Linear(2048, 500)),
('relu', nn.ReLU()),
('fc2', nn.Linear(500, 2)),
('output', nn.LogSoftmax(dim=1))
]))
model.classifier = classifier
criterion = nn.NLLLoss()
# Only train the classifier parameters, feature parameters are frozen
optimizer = optim.Adam(model.classifier.parameters(), lr=0.001)
model.to(device);
and the full error I am having
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-11-912dafb06827> in <module>
12
13 logps = model.forward(inputs)
---> 14 loss = criterion(logps, labels)
15 loss.backward()
16 optimizer.step()
~/anaconda3/envs/pytorch10/lib/python3.7/site-packages/torch/nn/modules/module.py in __call__(self, *input, **kwargs)
487 result = self._slow_forward(*input, **kwargs)
488 else:
--> 489 result = self.forward(*input, **kwargs)
490 for hook in self._forward_hooks.values():
491 hook_result = hook(self, input, result)
~/anaconda3/envs/pytorch10/lib/python3.7/site-packages/torch/nn/modules/loss.py in forward(self, input, target)
208 @weak_script_method
209 def forward(self, input, target):
--> 210 return F.nll_loss(input, target, weight=self.weight, ignore_index=self.ignore_index, reduction=self.reduction)
211
212
~/anaconda3/envs/pytorch10/lib/python3.7/site-packages/torch/nn/functional.py in nll_loss(input, target, weight, size_average, ignore_index, reduce, reduction)
1780 if size_average is not None or reduce is not None:
1781 reduction = _Reduction.legacy_get_string(size_average, reduce)
-> 1782 dim = input.dim()
1783 if dim < 2:
1784 raise ValueError('Expected 2 or more dimensions (got {})'.format(dim))
AttributeError: 'tuple' object has no attribute 'dim'