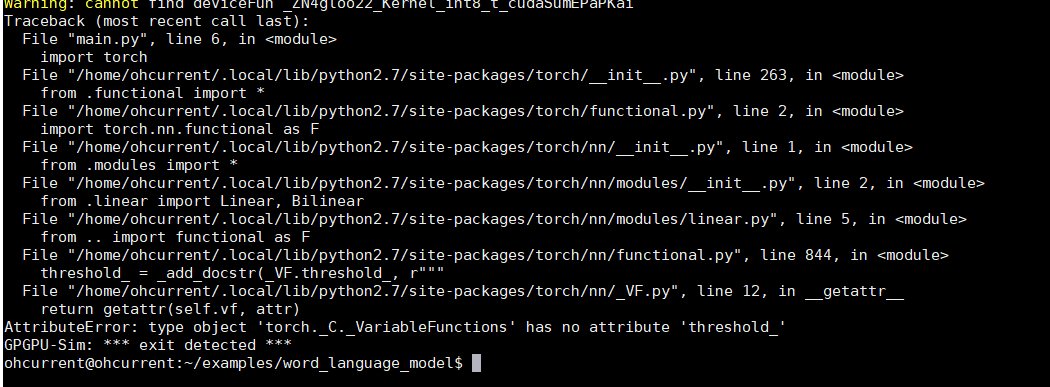
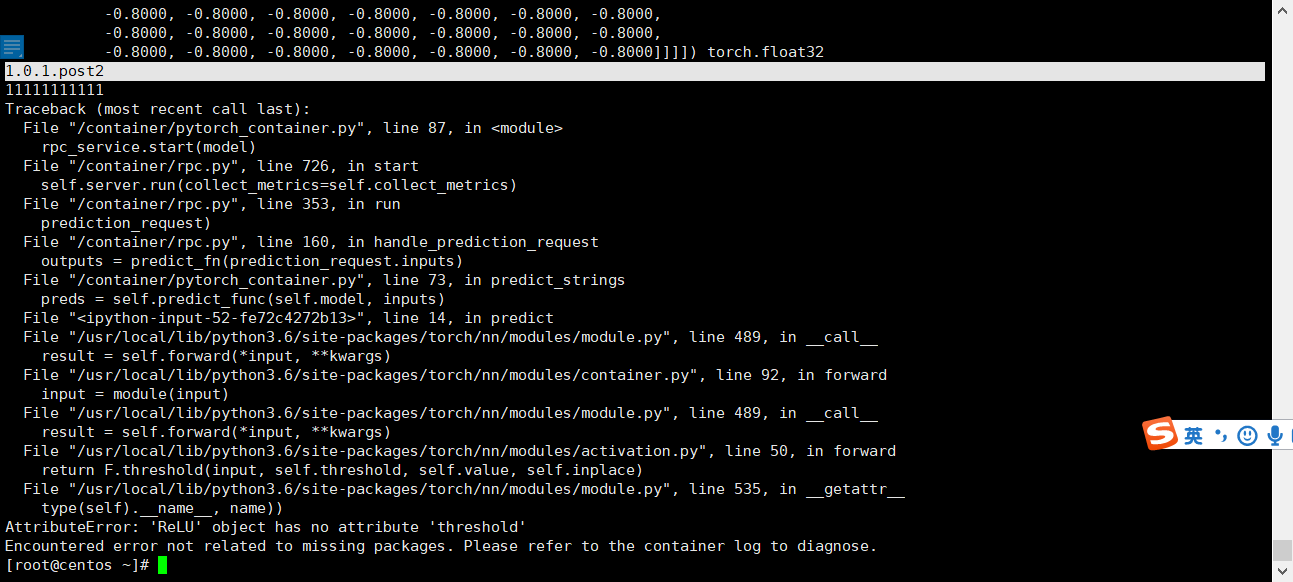
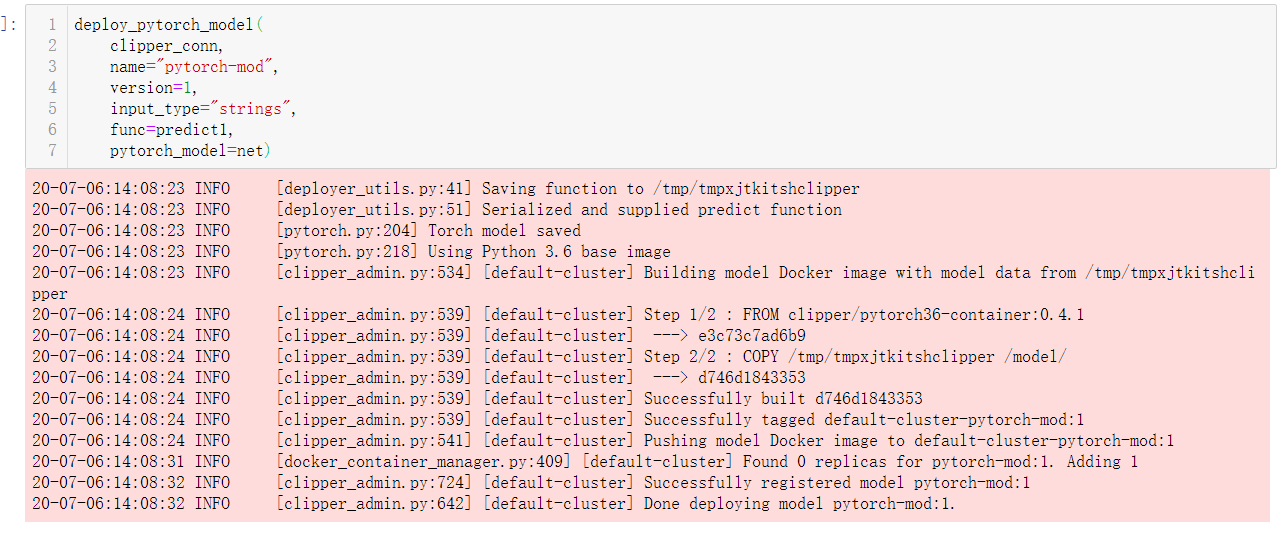
Thank you for your reply. I used the prediction service Clipper to make the prediction. At present, the default installed version of PyTorch is 1.0.1.Post2
So I want to know the root cause of this error and find a solution that doesn’t change the version
This is my call and deployment code
import os
import sys
import time
import torch
from torch import nn, optim
import torch.nn.functional as F
import torchvision
from torchvision import transforms
class GlobalAvgPool2d(nn.Module):
“”"
全局平均池化层
可通过将普通的平均池化的窗口形状设置成输入的高和宽实现
“”"
def __init__(self):
super(GlobalAvgPool2d, self).__init__()
def forward(self, x):
return F.avg_pool2d(x, kernel_size=x.size()[2:])
class FlattenLayer(torch.nn.Module):
def init(self):
super(FlattenLayer, self).init()
def forward(self, x): # x shape: (batch, *, *, ...)
return x.view(x.shape[0], -1)
class Residual(nn.Module):
def init(self, in_channels, out_channels, use_1x1conv=False, stride=1):
“”"
use_1×1conv: 是否使用额外的1x1卷积层来修改通道数
stride: 卷积层的步幅, resnet使用步长为2的卷积来替代pooling的作用,是个很赞的idea
“”"
super(Residual, self).init()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1, stride=stride)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1)
if use_1x1conv:
self.conv3 = nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride)
else:
self.conv3 = None
self.bn1 = nn.BatchNorm2d(out_channels)
self.bn2 = nn.BatchNorm2d(out_channels)
def forward(self, X):
Y = F.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
if self.conv3:
X = self.conv3(X)
return F.relu(Y + X)
def resnet_block(in_channels, out_channels, num_residuals, first_block=False):
‘’’
resnet block
num_residuals: 当前block包含多少个残差块
first_block: 是否为第一个block
一个resnet block由num_residuals个残差块组成
其中第一个残差块起到了通道数的转换和pooling的作用
后面的若干残差块就是完成正常的特征提取
‘’’
if first_block:
assert in_channels == out_channels # 第一个模块的输出通道数同输入通道数一致
blk =
for i in range(num_residuals):
if i == 0 and not first_block:
blk.append(Residual(in_channels, out_channels, use_1x1conv=True, stride=2))
else:
blk.append(Residual(out_channels, out_channels))
return nn.Sequential(*blk)
定义resnet模型结构
net = nn.Sequential(
nn.Conv2d(1, 32, kernel_size=3, stride=1, padding=1), # TODO: 缩小感受野, 缩channel
nn.BatchNorm2d(32),
nn.ReLU())
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2)) # TODO:去掉maxpool缩小感受野
然后是连续4个block
net.add_module(“resnet_block1”, resnet_block(32, 32, 2, first_block=True)) # TODO: channel统一减半
net.add_module(“resnet_block2”, resnet_block(32, 64, 2))
net.add_module(“resnet_block3”, resnet_block(64, 128, 2))
net.add_module(“resnet_block4”, resnet_block(128, 256, 2))
global average pooling
net.add_module(“global_avg_pool”, GlobalAvgPool2d())
fc layer
net.add_module(“fc”, nn.Sequential(FlattenLayer(), nn.Linear(256, 10)))
def load_data_fashion_mnist(batch_size, root=‘../data’):
“”“Download the fashion mnist dataset and then load into memory.”“”
normalize = transforms.Normalize(mean=[0.28], std=[0.35])
train_augs = transforms.Compose([
transforms.RandomCrop(28, padding=2),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
normalize
])
test_augs = transforms.Compose([
transforms.ToTensor(),
normalize
])
mnist_train = torchvision.datasets.FashionMNIST(root=root, train=True, download=True, transform=train_augs)
mnist_test = torchvision.datasets.FashionMNIST(root=root, train=False, download=True, transform=test_augs)
if sys.platform.startswith('win'):
num_workers = 0 # 0表示不用额外的进程来加速读取数据
else:
num_workers = 4
train_iter = torch.utils.data.DataLoader(mnist_train, batch_size=batch_size, shuffle=True, num_workers=num_workers)
test_iter = torch.utils.data.DataLoader(mnist_test, batch_size=batch_size, shuffle=False, num_workers=num_workers)
return train_iter, test_iter
batch_size = 1
train_iter, test_iter = load_data_fashion_mnist(batch_size, root=‘/root/.pytorch/F_MNIST_data’)
lr, num_epochs, lr_period, lr_decay = 0.01, 50, 5, 0.1
#optimizer = optim.Adam(net.parameters(), lr=lr)
optimizer = optim.SGD(net.parameters(), lr=lr, momentum=0.9, weight_decay=5e-4)
device = torch.device(‘cuda’ if torch.cuda.is_available() else ‘cpu’)
print(‘加载最优模型’)
net.load_state_dict(torch.load(‘model/best.pth’))
net = net.to(device)
print(‘inference测试集’)
net.eval()
id = 0
preds_list =
with torch.no_grad():
for X, y in test_iter:
batch_pred = list(net(X.to(device)).argmax(dim=1).cpu().numpy())
print(batch_pred)
for y_pred in batch_pred:
print(y_pred)
preds_list.append((id, y_pred))
id += 1
print(‘生成测试集评估文件’)
with open(‘result.csv’, ‘w’) as f:
f.write(‘ID,Prediction\n’)
for id, pred in preds_list:
f.write(‘{},{}\n’.format(id, pred))