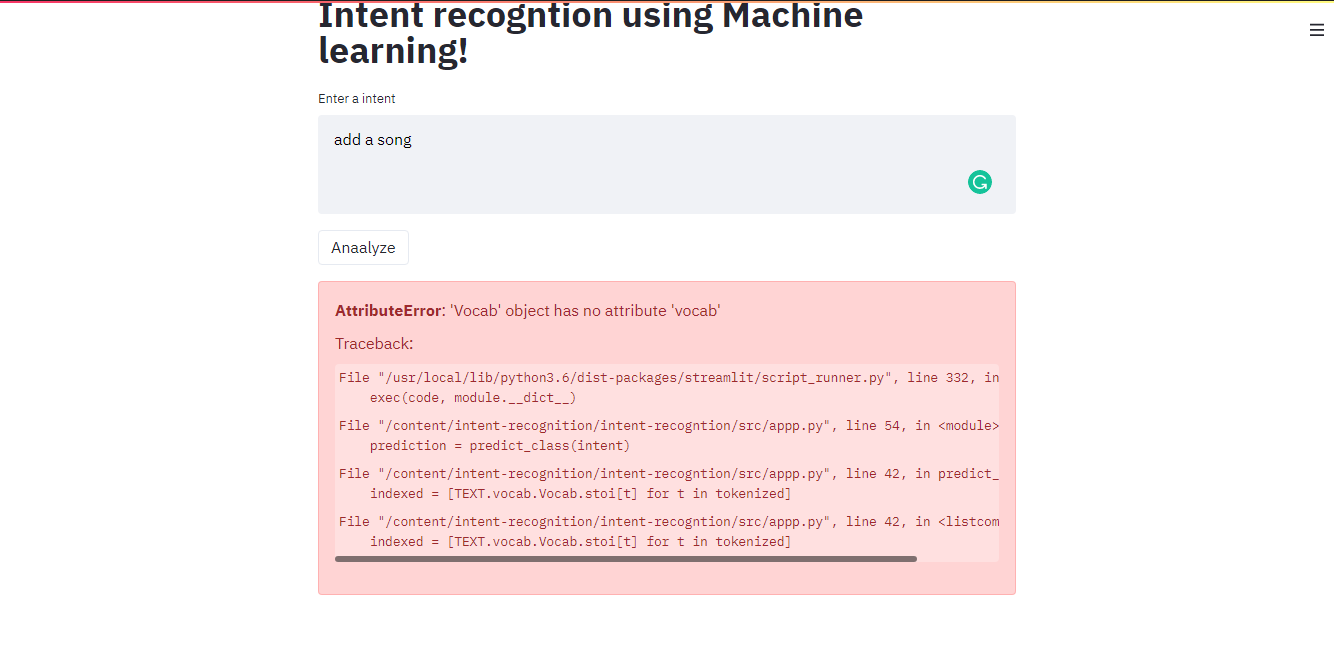
I have created a text classification model and also created a seperate vocabulary file when I try to create a streamlit model I get this error
code for app file
import re
import pickle
import spacy
import torchtext
import torch
import streamlit as st
from config import *
from models.cnn import CNN
from torchtext import vocab
try:
vocab._default_unk_index
except AttributeError:
def _default_unk_index():
return 0
vocab._default_unk_index = _default_unk_index
pretrained_model_path = "/content/drive/MyDrive/Models/INTENT/cnn-model.pt"
pretrained_vocab_path = "/content/drive/MyDrive/Models/INTENT/cnndict.pkl"
# load spacy's nlp model for tokenization
nlp = spacy.load("en")
# load the model
model = CNN(INPUT_DIM, EMBEDDING_DIM, N_FILTERS, FILTER_SIZES, OUTPUT_DIM, DROPOUT)
@st.cache()
def load_model(model_path):
"""
# load the pretrained model path
"""
return model.load_state_dict(torch.load(pretrained_model_path))
# load the pretrained vocab file
with open(pretrained_vocab_path, "rb") as f:
TEXT = pickle.load(f)
def predict_class(intent, model=model):
model.eval()
tokenized = [tok.text for tok in nlp.tokenizer(intent)]
indexed = [TEXT.vocab.Vocab.stoi[t] for t in tokenized]
tensor = torch.LongTensor(indexed).to(device)
tensor = tensor.unsqueeze(1)
preds = model(tensor)
max_pred = preds.argmax(dim=1)
return max_pred.item()
#streamlit --code
st.title("Intent recogntion using Machine learning!")
intent = st.text_area("Enter a intent","Type Here..")
if st.button("Anaalyze"):
with st.spinner("Analyzing the intent..."):
prediction = predict_class(intent)
if prediction==0:
st.success("Add to playlist")
elif prediction==1:
st.success("Book a Restaurent")
elif prediction==2:
st.success("Get weather info")
elif prediction==3:
st.success("Play music")
elif prediction==4:
st.success("Rate a book")
elif prediction==5:
st.success("Search for creative work")
elif prediction==6:
st.success("Search for screening event")```
Now how to avoid this error please help!