I’m trying to build MIR 1K dataset and train with DNN frame wise based.
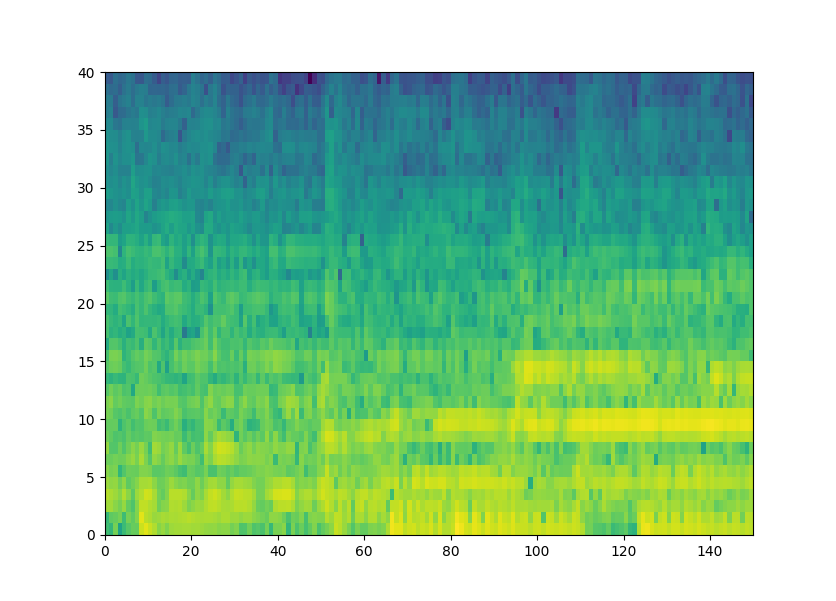
Given the spectrogram with feature data (40, 150) as below and label (150). eg. frame index 0 has feature (40, ) with MIDI label 68.
The above Mel spec and label is obtained as below.
class MIR1K(Dataset):
"""
offical document
frame size of 40ms -> 640 sample points
hop size of 20 ms -> 320 sample points
each 10ms hop size has one pitch vector
Args:
Dataset (_type_): return mel, pitch
"""
def __init__(self, transform=None, segment_len=150):
# def __init__(self, val_ratio:float):
self.audio_dir = DBPATH + MIRAUD + '/Wavfile/'
self.label_dir = DBPATH + MIRAUD + '/PitchLabel'
self.total_song = os.listdir(self.audio_dir)
self._transform = transform
self.o_sr = 0
self.segment_len = segment_len
# self.val_ratio = val_ratio
def __len__(self):
'return the fold song number'
return len(self.total_song)
def __getitem__(self, index):
songname = self._get_song(self.audio_dir, index)
print(songname)
audio_path = self._get_audio(songname)
pitch = self._get_label(songname)
audio, self.o_sr = librosa.load(audio_path, sr=None, mono=True)
if self._transform is None:
return torch.FloatTensor(audio), torch.FloatTensor(pitch)
else:
audio = self._transform(audio, self.o_sr)
# rescale rescale audio and pitch
shape_diff = audio.shape[1] - pitch.shape[0]
if (shape_diff) == 1:
audio = audio[:,1:]
elif (shape_diff) == 2:
audio = audio[:,1:-1]
else:
assert(shape_diff > 2)
# Segmemt mel-spectrogram into "segment_len" frames
if (audio.shape[1] > self.segment_len):
start = random.randint(0, audio.shape[1] - self.segment_len)
mel = torch.FloatTensor(audio[:,start:start+self.segment_len])
pitch = torch.FloatTensor(pitch[start:start+self.segment_len])
else:
mel = torch.FloatTensor(audio)
pitch = torch.FloatTensor(pitch)
return mel, pitch
# return audio, pitch
def _get_song(self, audio_dir, index):
return os.listdir(audio_dir)[index].split('.')[0]
def _get_audio(self, song):
if ".wav" in song:
return os.path.join(self.audio_dir, song)
return os.path.join(self.audio_dir, song + '.wav')
def _get_label(self, song):
pitch_label = np.loadtxt(os.path.join(self.label_dir, song + '.pv'))
# convert midi to frequency
pitch = 2**( (pitch_label - 69)/12) * 440
return pitch
Is there any tutorial to use the data and train frame wise ?