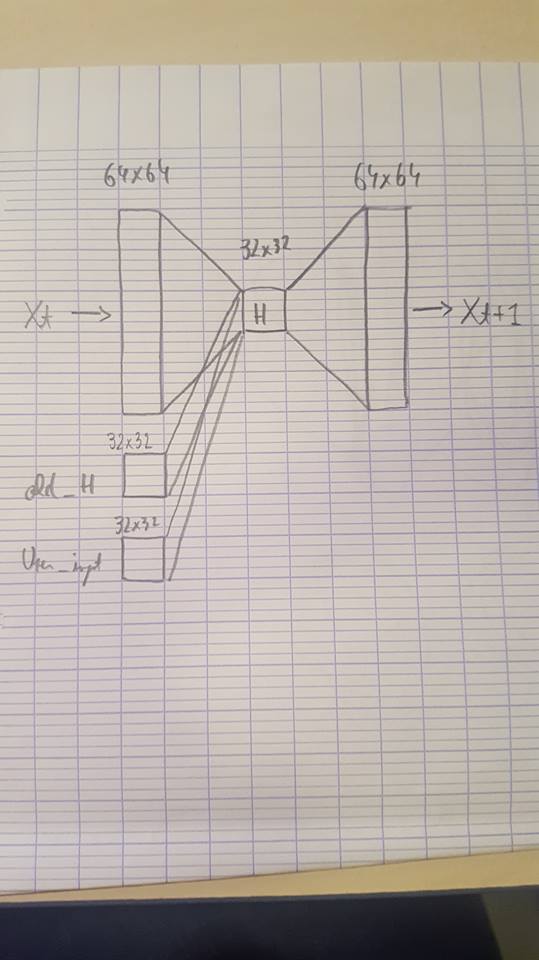
hi, I am currently building a predictive unit based around a 3 layers autoencoder :
class LPU_test(nn.Module): # end control LPU
def __init__(self, Encoder_size, Hidden_size, Decoder_size, User_input):
# simple autoencoder structure
super(LPU_test, self).__init__()
# ENC input : main sensory state (Encoder_size) the last hidden state and
# controlled user input
self.encoder = nn.Linear((Encoder_size + Hidden_size + User_input), (Hidden_size))
self.act_encoder = nn.Sigmoid()
self.decoder = nn.Linear(Hidden_size, Decoder_size)
self.act_decoder = nn.Sigmoid()
def forward(self, Xt, last_Hidden, User_input):
input_encoder = torch.cat((Xt, last_Hidden, User_input), 1)
encoder_process = self.encoder(input_encoder)
representation = self.act_decoder(encoder_process)
decoder_process = self.decoder(representation)
out_decoder = self.act_decoder(decoder_process)
return out_decoder, representation
the main input (Xt) is a (64x64) image i get from my camera :
cam = cv2.VideoCapture(0)
# init the system
ret, frame = cam.read(0)
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
frame = cv2.resize(frame, (64, 64))
the image is converted directly into a tensor using “input = torch.from_numpy(frame)”
i have created also artificial input to test my network :
old_H1 = torch.randn(32,32)
user = torch.randn(32,32)
I would like to know if my concatenation :
input_encoder = torch.cat((Xt, last_Hidden, User_input), 1)
is correct given the input (input, old_H1, and user) and the network
LPU_LAYER = LPU_test((64* 64), (32* 32), (64* 64), (32* 32))?
also i would like to know if it possible to give directly to the network a grayscale image converted into a tensor ?