Hello there,
I am currently dealing with image reconstruction using a simple Convolutional Autoencoder. The Autoencoder is split into two networks:
- The Encoder: Maps the input image to latent space with ReLU as last activation function
- The Decoder: Maps the latent variable back to the image space. Last activation function is tanh or sigmoid.
The data preprocessing step is: [transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))] The mean and std values were calculated channel wise on the training set.
To denormalize/ unnormalize the images, I used the following code which is closely related to Unnormalize images:
def denormalize(data, mean, std):
data_un = data.new(*data.size())
n_channel = data.shape[1]
for c in n_channel:
data_un[:,c] = data[:,c]*std[c] + mean[c]
return data_un
When I train the network (with MSE loss on MNIST) and look at the reconstructed images they do not match, although the general structure looks very similar. Note that as activation functions in the final layer of the decoder, I tried both: sigmoid and tanh. After the normalization step of the input data, the images are shifted, so that they are in [-1,1]. For that reason, I thought it would make more sense to use an Tanh instead of a Sigmoid. However, when I denormalize the reconstructed images, they look off.
The first figure shows the sigmoid example, the latter figure displays the tanh example.
Note that, the first row shows the input images after they have been normalized and unnormalized, the second row shows the same images after reconstruction and unormalization.
Sigmoid:

Tanh:
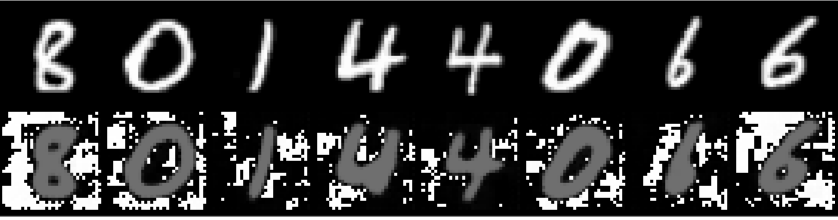
The code below was used to log the images to Tensorboard:
dec_out: decoder output
data_nm: the normalized images given as input to the encoder
images_normalized = torch.concat([data_nm[:8, ].detach(), dec_out[:8, ].detach()])
images_unnormalized = denormalize(data=images_normalized, mean=(0.1307,), std=(0.3081,))
img_grid = make_grid(images_unnormalized, nows=8)
Do you have any idea why this happens and whether it is a good idea to denormalize the reconstructed images? Does it make sense to scale the input images after normalization back to [0,1]? Or is there something else that I am missing?
Thank you for any hints ![]()