I am trying to learn a parameter which is one element of a bigger matrix. The loss function does not directly use the learnable parameter, but a matrix having this parameter.
Simplified code snippet is given below to reproduce the error
import torch as t
import torch
from matplotlib import pyplot as plt
param = t.tensor([1], dtype=t.float, requires_grad=True)
a = torch.tensor([[param, 0],[0, 2]], dtype=t.float, requires_grad= True)
b = torch.tensor([[5], [6]], dtype=t.float, requires_grad = True)
c = torch.tensor([[50], [12]], dtype=t.float, requires_grad = True)
def calc_loss(A, B, C):
X = torch.sqrt(torch.mean((torch.matmul(A,B)-C)**2))
return t.abs(X)
optimizer = t.optim.Adam([param], lr=1)
n = 10
values = t.zeros(n, dtype=t.float)
for i in range(n):
optimizer.zero_grad()
loss = calc_loss(a, b, c)
print(f"gradient of the complex number are {param.grad}")
print(f"calculated loss value is {loss}")
loss.backward()
optimizer.step()
values[i] = param.detach()
# Plot the results
plt.plot(values, label='Learnable parameter')
plt.legend()
plt.xlabel('Iteration')
plt.ylabel('Parameter')
plt.show()
gradient of the complex number are None
calculated loss value is 31.819805145263672
gradient of the complex number are None
calculated loss value is 31.819805145263672
gradient of the complex number are None
calculated loss value is 31.819805145263672
gradient of the complex number are None
calculated loss value is 31.819805145263672
gradient of the complex number are None
calculated loss value is 31.819805145263672
gradient of the complex number are None
calculated loss value is 31.819805145263672
gradient of the complex number are None
calculated loss value is 31.819805145263672
gradient of the complex number are None
calculated loss value is 31.819805145263672
gradient of the complex number are None
calculated loss value is 31.819805145263672
gradient of the complex number are None
calculated loss value is 31.819805145263672
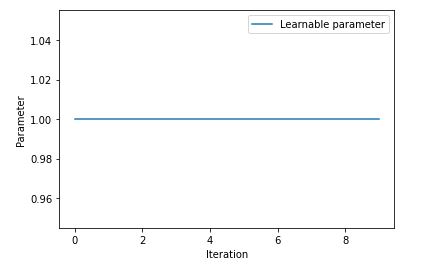
The expected value for param is 10, but seems the gradient is always None. Somewhere the computational graph is brocken, but I am not able to track it.

