Hi everyone! I’m trying to implement LISTA network (deepunfolded Iterative Soft Thresholding): in order to do so I implemented a custom layer and a network as follows:
Custom layer:
class LISTA_LAYER(nn.Module):
def __init__(self, A):
super().__init__()
# Initialization of the learnable parameters
self.W1 = nn.Linear(A.shape[0], A.shape[1], bias=False)
self.W2 = nn.Linear(A.shape[1], A.shape[1], bias=False)
self.beta = nn.Parameter(torch.ones(1, 1, 1), requires_grad=True)
self.mu = nn.Parameter(torch.ones(1, 1, 1), requires_grad=True)
# Apply Xavier uniform initialization
nn.init.xavier_uniform_(self.W1.weight)
nn.init.xavier_uniform_(self.W2.weight)
def _shrink(self, x, beta):
return beta * F.softshrink(x / beta, lambd=1)
def forward(self, y, x):
if x is None:
x = torch.zeros(y.shape[0], A.shape[1], requires_grad=True)
return self._shrink(x - self.mu*(self.W1(y) + self.W2(x)),
self.beta)
Custom network:
class LISTA_Net(nn.Module):
def __init__(self, A, K = 5):
super(LISTA_Net, self).__init__()
# Number of layers <-> iterations
self.K = K
# Layers
self.LISTA_layers = nn.ModuleList([LISTA_LAYER(A) for _ in range(self.K + 1)])
def forward(self, y):
x = self.LISTA_layers[0].forward(y,None)
for i in range(1, self.K + 1):
x = self.LISTA_layers[i].forward(y,x)
return x
The idea of LISTA is embodied in the following computational graph:
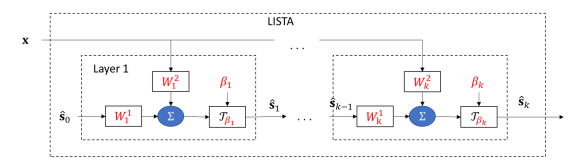
When I work out the main train loop I have None gradients everywhere, could you please help me figure out why? I mean, I checked that all the variables are seen as leaves of the computational graph looking at
list([p for p in model.parameters() if p.is_leaf])
at seing that all network parameters are in this list.
This is the main train loop once I instantiated the model:
optimizer = torch.optim.SGD(
model.parameters(),
lr=5e-05,
momentum=0.9,
weight_decay=0,
)
scheduler = torch.optim.lr_scheduler.StepLR(
optimizer, step_size=50, gamma=0.1
)
loss_train = np.zeros((num_epochs,))
loss_test = np.zeros((num_epochs,))
# Main loop
for epoch in range(num_epochs):
model.train()
train_loss = 0
for _, (b_x, b_s) in enumerate(train_loader):
s_hat = model.forward(b_x)
loss = F.mse_loss(s_hat, b_s, reduction="sum")
optimizer.zero_grad()
loss.backward()
optimizer.step()
model.zero_grad()
train_loss += loss.data.item()
loss_train[epoch] = train_loss / len(train_loader.dataset)
scheduler.step()
Thanks in advance ![]()