Hi, I am trying to figure how the tensor gradient is calculated when using the einsum operator. Can someone point me towards documentation for this or alteast the internal implementation in source code?
Good question, actually one of the exercises in my advanced autograd class.
The answer lies in the autograd graph:
x = torch.randn(5,5, requires_grad=True)
y = torch.randn(5,5, requires_grad=True)
a = torch.einsum('ik,kj->ij', x, y)
a
will show you that the grad_fn of a it is some view backward. And indeed, the graph looks like this:
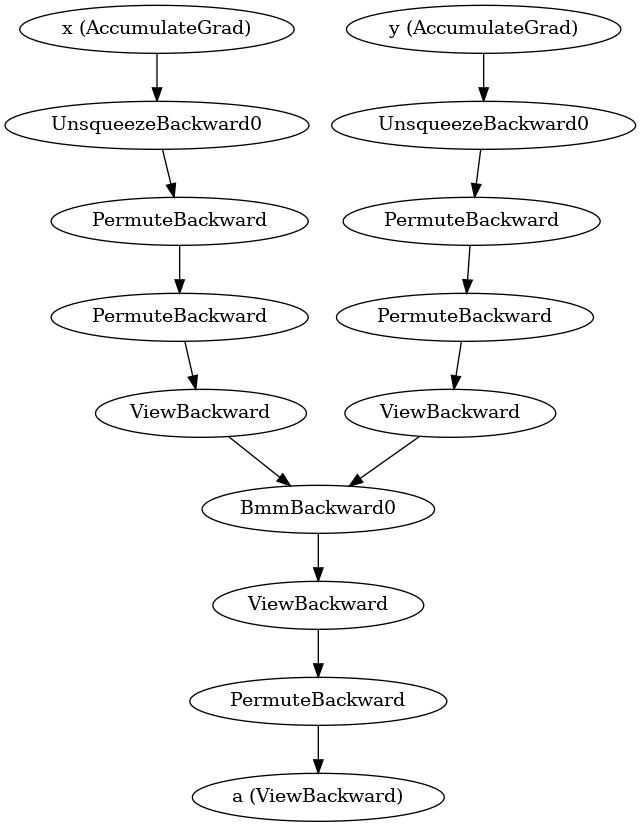
einsum reduces to reshaping operations and batch matrix multiplication in bmm.
Like when you write your own computation in Python, PyTorch actually keeps track of the calls to “explicitly differentiable functions” and then computes the backward piece by piece.
The reduction is actually the other way round as in NumPy where bmm reduces to einsum.
If you look at the PyTorch einsum implementation you see that (save some optimizations which would have been better put in sumproduct_pair IMHO) it rearranges some things and then calls sumproduct_pair. That in turn could have a very simple explicit derivative with expand + sumproduct_pair.
Best regards
Thomas
1 Like