I am building a network with several graph convolutions involved in each layer.
A graph convolution requires a graph signal matrix X and an adjacency_matrix adj_mx
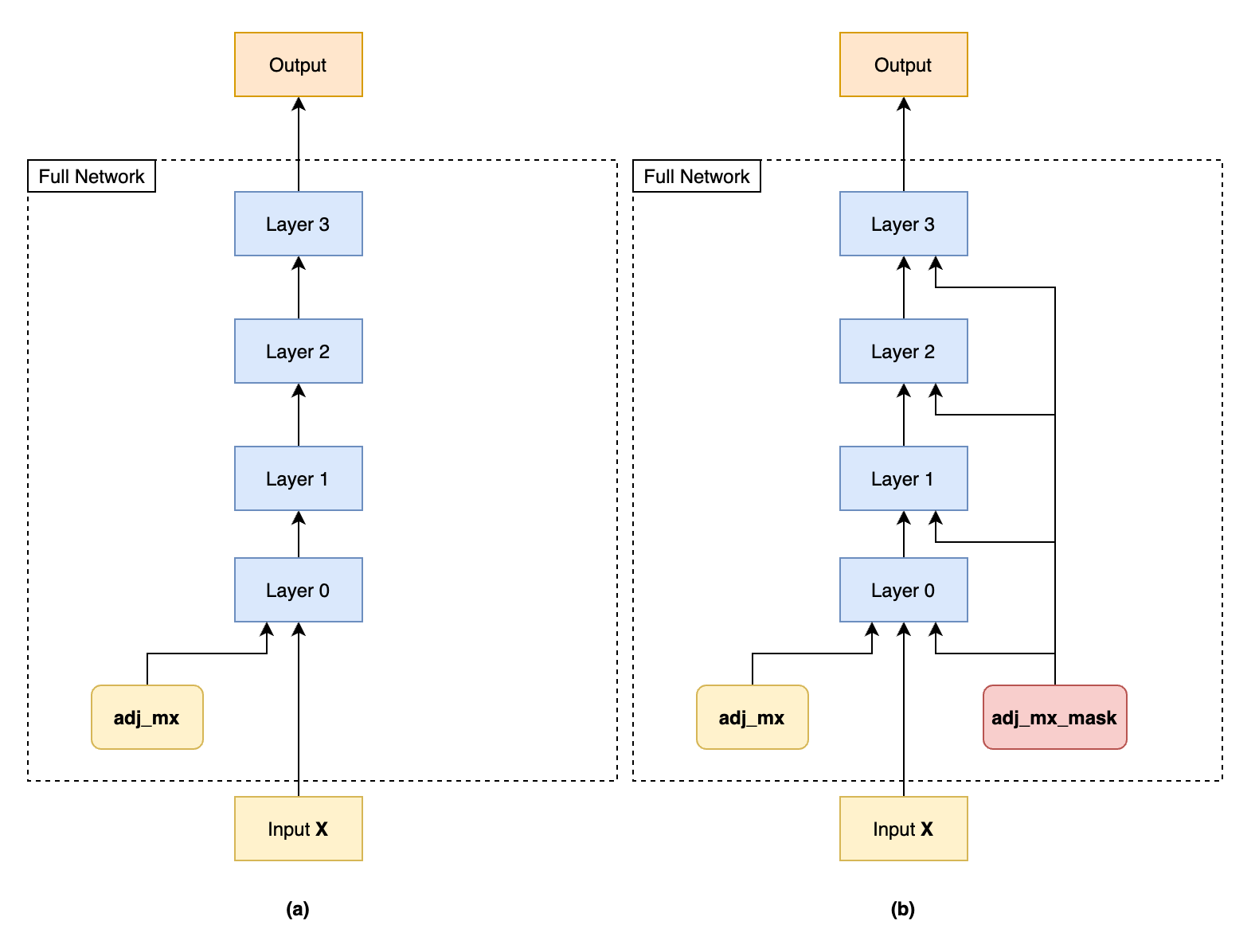
The network simplified computation graph looks as follow:
In (a) the network has self.adj_mx being used in all layers.
In (b) I added a learnable mask adj_mx_mask for the adj_mx.
We have therefore self.adj_mx_mask = nn.Parameter(…) same shape as self.adj_mx
In each layer, self.adj_mx = self.adj_mx * self.adj_mx_mask
The problem is, with (a), loss.backward() works perfectly well.
With (b) I get the error to use loss.backward(retain_graph=True) which makes the training process way slower.
I need a way to add this learnable mask without having to make the training so slow.
This seems dubious, as it replaces the parameter(?) self.adj_mx with the multiplied version.
As a rule of thumb, assigning things in forward is unlikely to be the right thing to do.
This is a rule of thumb I will remember for sure.
Any idea on the underlying “why” of this? (self.adj_mx is a torch.Tensor btw, self.adj_mx_mask is a parameter)
Just replacing where I used self.adj_mx by self.adj_mx * self.adj_mx_mask without explicit assigning solved the issue.
Vielen Dank!
It would be really awesome that you, @ptrblck, @albanD, @rasbt (and many more) compile a list of “rules of thumb” for PyTorch given your extensive expertise especially debugging/solving problems on this forum.
This will also save you a lot of time while replying to issues because you can always refer to a specific “rule” in your list that people can check with related references.
@ptrblck and I have an imaginary PyTorch book that covers everything around PyTorch except deep learning. It’s an instant classic.
It has an extensive chapter on the autograd graph answering why you sometimes get the inplace errors, how to avoid “trying to backward through the graph a second time” etc. (I think it’s chapter two or three.)
The trouble is – aside from the book not being publicly accessible – that knowing which rule of thumb is the one that solves a given problem is harder than providing a list of rules of thumb. There is a sizeable number of questions on the forum which go “how can I do x – use function y”. If it was easy to find y in the documentation when thinking about x, one would not see questions like these in the forums (and while the documentation can always be improved, I don’t think incompleteness or imperfection are the main reasons for this).
There also is a thread somewhere in the forum around style-guide or best practices where – somewhat similarly – I didn’t think that tick-lists work for that.