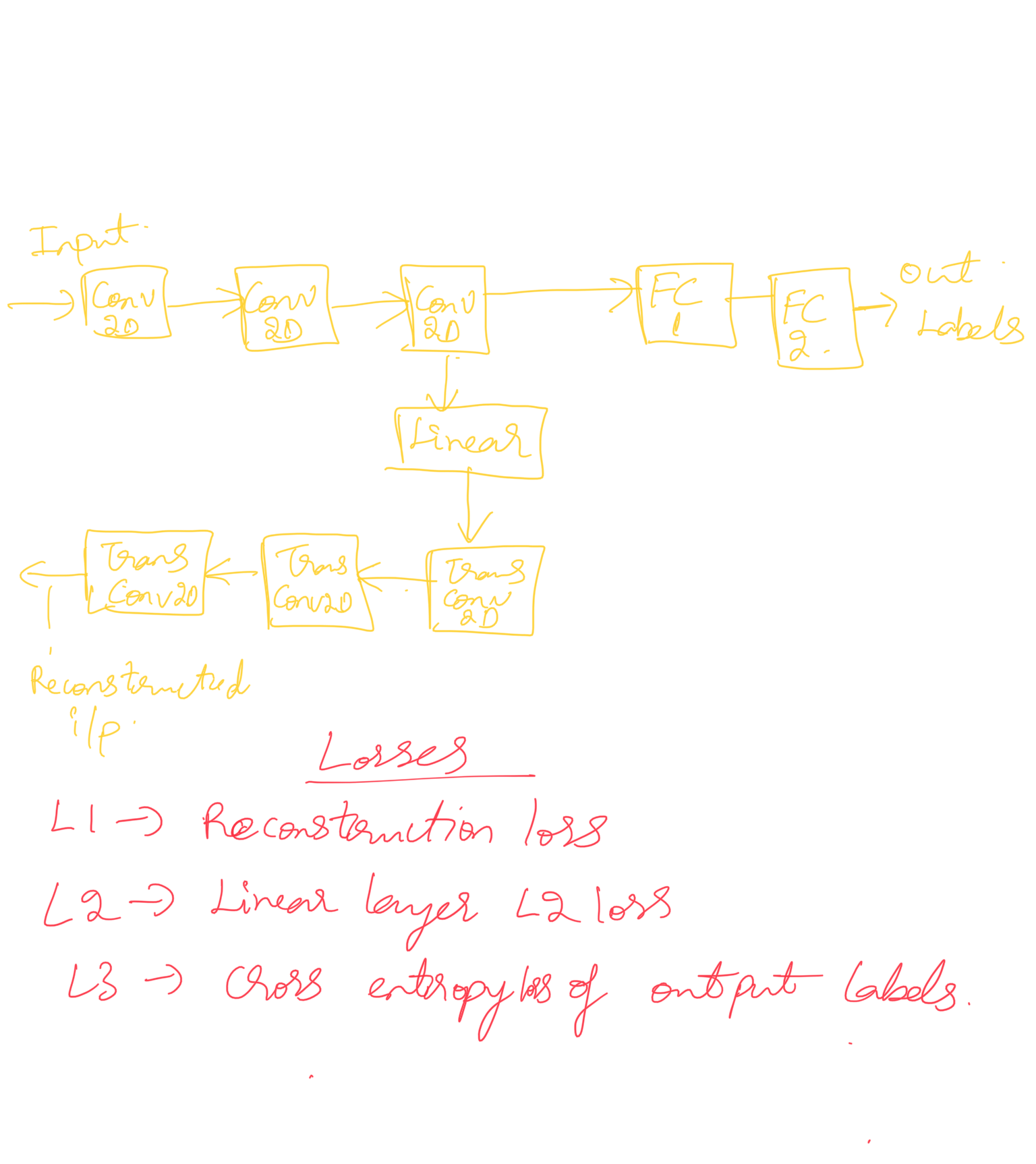
I have a network as follows.
Please don’t mind the picture representation of the network.
As in the pic, I have three loss functions. To do gradient descent, can I add all the three losses and form a loss L and do L.backward(). Or should I call backward individually on each loss?
You need to specify parameters of each of loss function (say l1(w1), l2(w2)) in the corresponding optimizer (say optim1(w1), optim2(w2)) and then find the gradients of both loss functions with respect to each parameter (l1.backward(), and l2.backward()) and then update each parameter (optim1.step() and optim2.step()).
So adding up the losses and back propagating just once doesn’t work ?
I think I didn’t understand your question at the first place. If you have only one set of parameters and one graph, you should basically add up loss functions (with weights probably based on their importance) and operate back-propagation normally. If you have two different graphs with different loss functions, the previous solution may work. I hope it helps.
Sorry if my question wasn’t clear. It is like I have a single graph. But I am calculating different losses at different points in the network as shown above. So I can now add all the losses and back propagate it through one backward() call. This is my understanding.