Hello guys, we encounter a wired problem regarding to the backend choice for Distributed Training recently. Any help or suggestion is appreciated!
At the beginning of our code, we set backend to ‘nccl’ for better performance, as
torch.distributed.init_process_group(backend='nccl')
synchronize()
During training, we accidentally find that the actual backend being used is ‘gloo’, and the profiling validate this information.
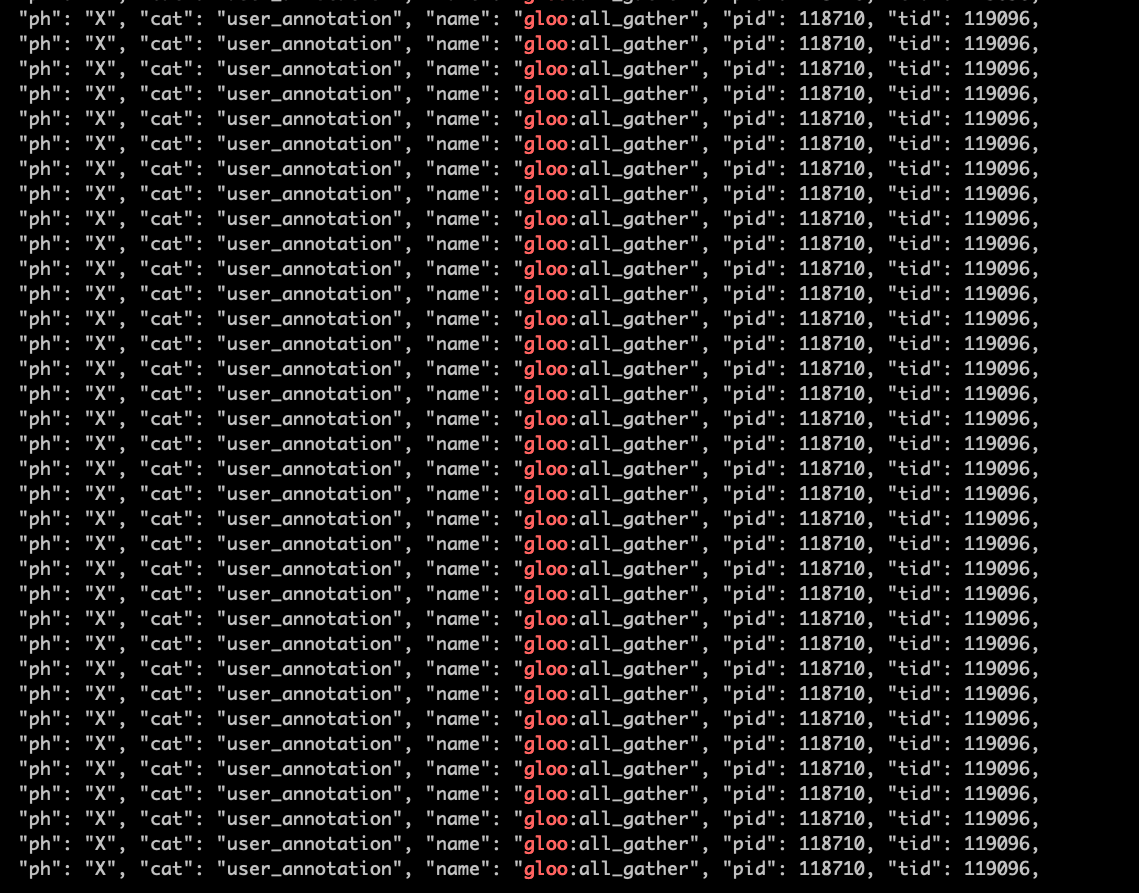
We never set ‘gloo’ in our code, why does this happen? Thank you very much for your help!