I don’t see how open source libraries “break” in this case, as the issue is caused by a missing ptxas dependency in the binaries.
If I’m not mistaken, the release engineering team is already working on its support in the nightly binaries, but I also don’t know what the status is or when it will be added.
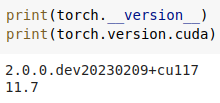
By today still same issue on Collab:
Thanks for the support.
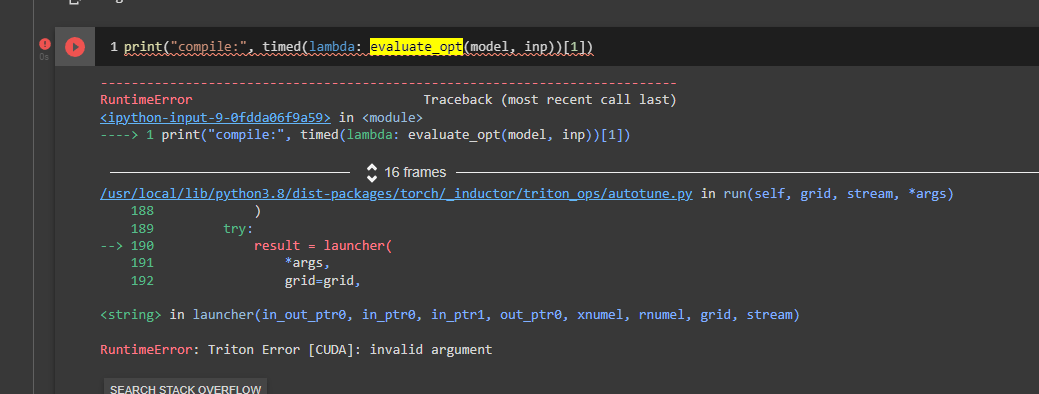
I have the similar problems. I try to compile a Mask R-CNN type model and receive the following error:
[2023-02-17 15:38:56,553] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing forward
[2023-02-17 15:38:56,796] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing forward
[2023-02-17 15:38:56,803] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing forward_features
[2023-02-17 15:38:56,839] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing <graph break in forward_features>
[2023-02-17 15:38:56,907] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing <graph break in forward_features>
[2023-02-17 15:39:04,874] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo done tracing <graph break in forward_features> (RETURN_VALUE)
[2023-02-17 15:39:04,972] torch._dynamo.output_graph: [INFO] Step 2: calling compiler function debug_wrapper
/usr/local/lib/python3.9/dist-packages/torch/_inductor/compile_fx.py:89: UserWarning: TensorFloat32 tensor cores for float32 matrix multiplication available but not enabled. Consider setting `torch.set_float32_matmul_precision('high')` for better performance.
warnings.warn(
[2023-02-17 15:39:23,223] torch._inductor.compile_fx: [INFO] Step 3: torchinductor compiling FORWARDS graph 0
concurrent.futures.process._RemoteTraceback:
"""
Traceback (most recent call last):
File "/usr/lib/python3.9/concurrent/futures/process.py", line 246, in _process_worker
r = call_item.fn(*call_item.args, **call_item.kwargs)
File "/usr/local/lib/python3.9/dist-packages/torch/_inductor/codecache.py", line 525, in _worker_compile
kernel.precompile(warm_cache_only_with_cc=cc)
File "/usr/local/lib/python3.9/dist-packages/torch/_inductor/triton_ops/autotune.py", line 67, in precompile
self.launchers = [
File "/usr/local/lib/python3.9/dist-packages/torch/_inductor/triton_ops/autotune.py", line 68, in <listcomp>
self._precompile_config(c, warm_cache_only_with_cc)
File "/usr/local/lib/python3.9/dist-packages/torch/_inductor/triton_ops/autotune.py", line 81, in _precompile_config
triton.compile(
File "/usr/local/lib/python3.9/dist-packages/triton/compiler.py", line 1256, in compile
asm, shared, kernel_name = _compile(fn, signature, device, constants, configs[0], num_warps, num_stages,
File "/usr/local/lib/python3.9/dist-packages/triton/compiler.py", line 901, in _compile
name, asm, shared_mem = _triton.code_gen.compile_ttir(backend, module, device, num_warps, num_stages, extern_libs, cc)
RuntimeError: Triton requires CUDA 11.4+
"""
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/usr/local/lib/python3.9/dist-packages/torch/_dynamo/output_graph.py", line 692, in call_user_compiler
compiled_fn = compiler_fn(gm, self.fake_example_inputs())
File "/usr/local/lib/python3.9/dist-packages/torch/_dynamo/debug_utils.py", line 1054, in debug_wrapper
compiled_gm = compiler_fn(gm, example_inputs)
File "/usr/local/lib/python3.9/dist-packages/torch/__init__.py", line 1368, in __call__
return self.compile_fn(model_, inputs_, config_patches=self.config)
File "/usr/local/lib/python3.9/dist-packages/torch/_inductor/compile_fx.py", line 426, in compile_fx
return aot_autograd(
File "/usr/local/lib/python3.9/dist-packages/torch/_dynamo/optimizations/training.py", line 66, in compiler_fn
cg = aot_module_simplified(gm, example_inputs, **kwargs)
File "/usr/local/lib/python3.9/dist-packages/torch/_functorch/aot_autograd.py", line 2483, in aot_module_simplified
compiled_fn = create_aot_dispatcher_function(
File "/usr/local/lib/python3.9/dist-packages/torch/_dynamo/utils.py", line 162, in time_wrapper
r = func(*args, **kwargs)
File "/usr/local/lib/python3.9/dist-packages/torch/_functorch/aot_autograd.py", line 2180, in create_aot_dispatcher_function
compiled_fn = compiler_fn(flat_fn, fake_flat_args, aot_config)
File "/usr/local/lib/python3.9/dist-packages/torch/_functorch/aot_autograd.py", line 1411, in aot_wrapper_dedupe
return compiler_fn(flat_fn, leaf_flat_args, aot_config)
File "/usr/local/lib/python3.9/dist-packages/torch/_functorch/aot_autograd.py", line 1688, in aot_dispatch_autograd
compiled_fw_func = aot_config.fw_compiler(
File "/usr/local/lib/python3.9/dist-packages/torch/_dynamo/utils.py", line 162, in time_wrapper
r = func(*args, **kwargs)
File "/usr/local/lib/python3.9/dist-packages/torch/_inductor/compile_fx.py", line 401, in fw_compiler
return inner_compile(
File "/usr/local/lib/python3.9/dist-packages/torch/_dynamo/debug_utils.py", line 594, in debug_wrapper
compiled_fn = compiler_fn(gm, example_inputs)
File "/usr/local/lib/python3.9/dist-packages/torch/_inductor/debug.py", line 239, in inner
return fn(*args, **kwargs)
File "/usr/lib/python3.9/contextlib.py", line 79, in inner
return func(*args, **kwds)
File "/usr/local/lib/python3.9/dist-packages/torch/_inductor/compile_fx.py", line 155, in compile_fx_inner
compiled_fn = graph.compile_to_fn()
File "/usr/local/lib/python3.9/dist-packages/torch/_inductor/graph.py", line 570, in compile_to_fn
return self.compile_to_module().call
File "/usr/local/lib/python3.9/dist-packages/torch/_dynamo/utils.py", line 162, in time_wrapper
r = func(*args, **kwargs)
File "/usr/local/lib/python3.9/dist-packages/torch/_inductor/graph.py", line 559, in compile_to_module
mod = PyCodeCache.load(code)
File "/usr/local/lib/python3.9/dist-packages/torch/_inductor/codecache.py", line 504, in load
exec(code, mod.__dict__, mod.__dict__)
File "/tmp/torchinductor_root/ds/cdsqx7rlna6a3exrfewym2i3rb2b6mxqyoyja5ctaezbm4m5aowt.py", line 6971, in <module>
async_compile.wait(globals())
File "/usr/local/lib/python3.9/dist-packages/torch/_inductor/codecache.py", line 691, in wait
scope[key] = result.result()
File "/usr/local/lib/python3.9/dist-packages/torch/_inductor/codecache.py", line 549, in result
self.future.result()
File "/usr/lib/python3.9/concurrent/futures/_base.py", line 446, in result
return self.__get_result()
File "/usr/lib/python3.9/concurrent/futures/_base.py", line 391, in __get_result
raise self._exception
RuntimeError: Triton requires CUDA 11.4+
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/notebooks/prediction_net/tool/main.py", line 141, in <module>
main()
File "/notebooks/prediction_net/tool/main.py", line 113, in main
total_iter = train_one_epoch(epoch, cfg, train_loader, network,
File "/notebooks/prediction_net/tool/engine.py", line 122, in train_one_epoch
outputs = model(inputs, gts=gts)
File "/usr/local/lib/python3.9/dist-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/usr/local/lib/python3.9/dist-packages/torch/_dynamo/eval_frame.py", line 82, in forward
return self.dynamo_ctx(self._orig_mod.forward)(*args, **kwargs)
File "/usr/local/lib/python3.9/dist-packages/torch/_dynamo/eval_frame.py", line 209, in _fn
return fn(*args, **kwargs)
File "/notebooks/prediction_net/tool/../multimodal/models/detectors/simple_fpn.py", line 73, in forward
features = self.backbone(input_data)
File "/usr/local/lib/python3.9/dist-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/notebooks/prediction_net/tool/../multimodal/models/backbones/maxxvit.py", line 1219, in forward
x = self.forward_features(x)
File "/notebooks/prediction_net/tool/../multimodal/models/backbones/maxxvit.py", line 1211, in forward_features
outs = OrderedDict()
File "/usr/local/lib/python3.9/dist-packages/torch/_dynamo/eval_frame.py", line 330, in catch_errors
return callback(frame, cache_size, hooks)
File "/usr/local/lib/python3.9/dist-packages/torch/_dynamo/convert_frame.py", line 403, in _convert_frame
result = inner_convert(frame, cache_size, hooks)
File "/usr/local/lib/python3.9/dist-packages/torch/_dynamo/convert_frame.py", line 103, in _fn
return fn(*args, **kwargs)
File "/usr/local/lib/python3.9/dist-packages/torch/_dynamo/convert_frame.py", line 261, in _convert_frame_assert
return _compile(
File "/usr/local/lib/python3.9/dist-packages/torch/_dynamo/utils.py", line 162, in time_wrapper
r = func(*args, **kwargs)
File "/usr/local/lib/python3.9/dist-packages/torch/_dynamo/convert_frame.py", line 323, in _compile
out_code = transform_code_object(code, transform)
File "/usr/local/lib/python3.9/dist-packages/torch/_dynamo/bytecode_transformation.py", line 339, in transform_code_object
transformations(instructions, code_options)
File "/usr/local/lib/python3.9/dist-packages/torch/_dynamo/convert_frame.py", line 310, in transform
tracer.run()
File "/usr/local/lib/python3.9/dist-packages/torch/_dynamo/symbolic_convert.py", line 1715, in run
super().run()
File "/usr/local/lib/python3.9/dist-packages/torch/_dynamo/symbolic_convert.py", line 564, in run
and self.step()
File "/usr/local/lib/python3.9/dist-packages/torch/_dynamo/symbolic_convert.py", line 527, in step
getattr(self, inst.opname)(inst)
File "/usr/local/lib/python3.9/dist-packages/torch/_dynamo/symbolic_convert.py", line 1781, in RETURN_VALUE
Torch.version.cuda shows 11.6