Thanks for the code.
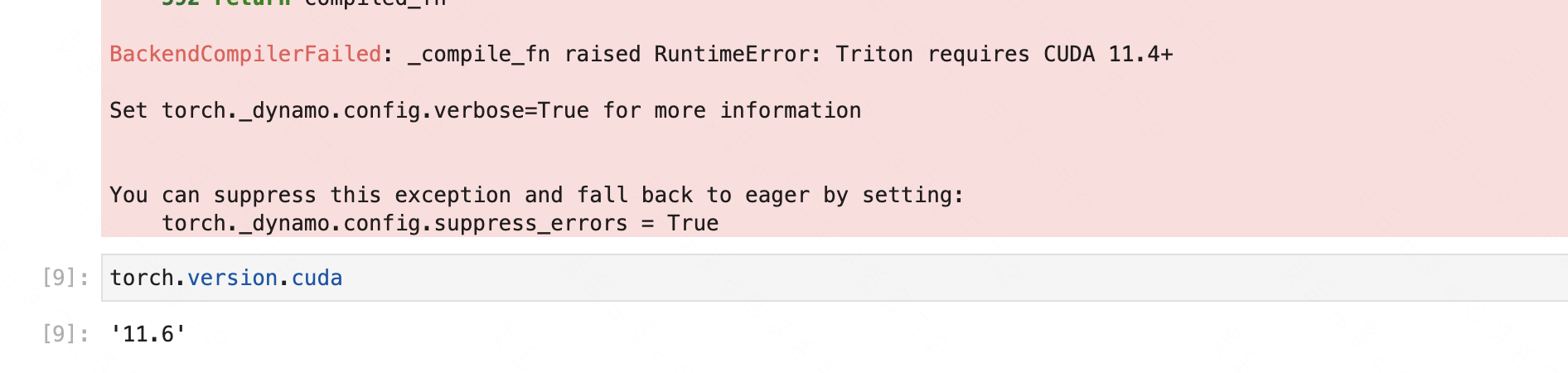
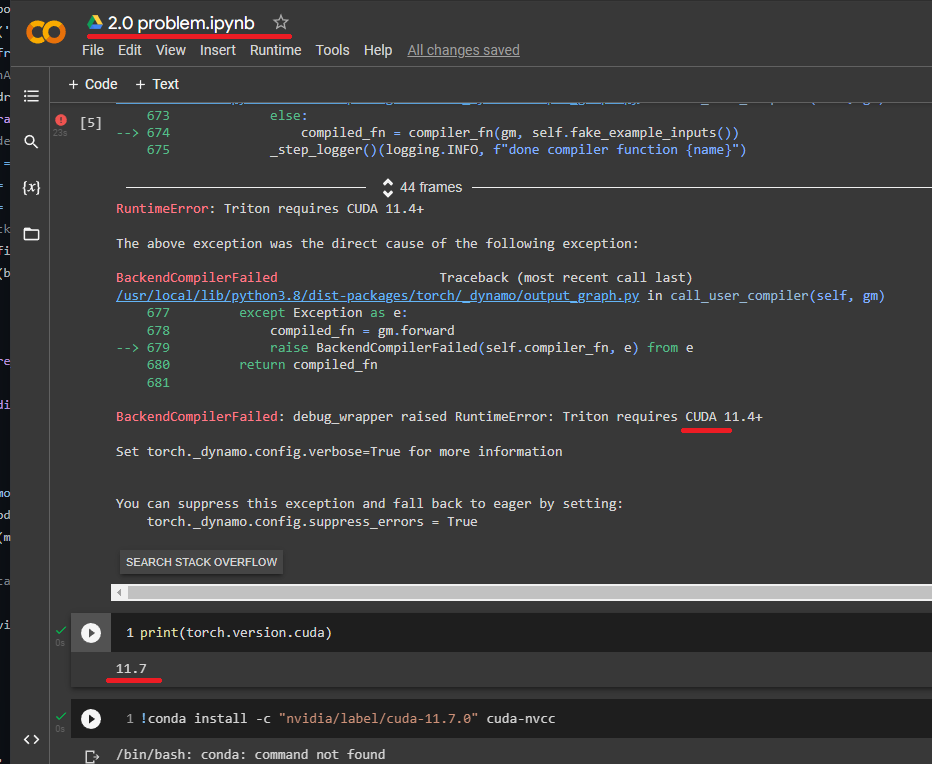
I cannot reproduce it with a current nightly conda binary using 11.6.
Env information:
python -m torch.utils.collect_env
Collecting environment information...
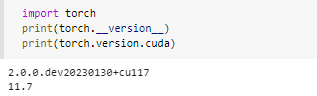
PyTorch version: 1.14.0.dev20221208
Is debug build: False
CUDA used to build PyTorch: 11.6
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.4 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: version 3.21.3
Libc version: glibc-2.31
Python version: 3.8.15 | packaged by conda-forge | (default, Nov 22 2022, 08:49:35) [GCC 10.4.0] (64-bit runtime)
Python platform: Linux-5.13.0-41-generic-x86_64-with-glibc2.10
Is CUDA available: True
CUDA runtime version: 11.6.124
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA GeForce RTX 3090
Nvidia driver version: 515.43.04
cuDNN version: Probably one of the following:
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn.so.8.5.0
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.5.0
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.5.0
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.5.0
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.5.0
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.5.0
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.5.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.5
[pip3] torch==1.14.0.dev20221208
[pip3] torchvision==0.15.0.dev20221208
[conda] blas 2.116 mkl conda-forge
[conda] blas-devel 3.9.0 16_linux64_mkl conda-forge
[conda] libblas 3.9.0 16_linux64_mkl conda-forge
[conda] libcblas 3.9.0 16_linux64_mkl conda-forge
[conda] liblapack 3.9.0 16_linux64_mkl conda-forge
[conda] liblapacke 3.9.0 16_linux64_mkl conda-forge
[conda] mkl 2022.1.0 h84fe81f_915 conda-forge
[conda] mkl-devel 2022.1.0 ha770c72_916 conda-forge
[conda] mkl-include 2022.1.0 h84fe81f_915 conda-forge
[conda] numpy 1.23.5 py38h7042d01_0 conda-forge
[conda] pytorch 1.14.0.dev20221208 py3.8_cuda11.6_cudnn8.3.2_0 pytorch-nightly
[conda] pytorch-cuda 11.6 h867d48c_0 pytorch-nightly
[conda] pytorch-mutex 1.0 cuda pytorch-nightly
[conda] torchtriton 2.0.0+0d7e753227 py38 pytorch-nightly
[conda] torchvision 0.15.0.dev20221208 py38_cu116 pytorch-nightly
python -c "import torch; print(torch.__version__); print(torch.version.cuda)"
1.14.0.dev20221208
11.6
Output:
python main.py
/opt/miniforge3/envs/nightly_conda_cuda116/lib/python3.8/site-packages/torch/_dynamo/eval_frame.py:366: UserWarning: TensorFloat32 tensor cores for float32 matrix multiplication available but not enabled.Consider setting `torch.set_float32_matmul_precision('high')`
warnings.warn(
tensor([[2.6126e-02, 5.6818e-01, 0.0000e+00, 2.6177e-01, 4.0566e-01, 0.0000e+00,
5.5200e-01, 0.0000e+00, 0.0000e+00, 2.0061e-01],
[0.0000e+00, 1.4974e-01, 0.0000e+00, 0.0000e+00, 0.0000e+00, 2.4196e-01,
0.0000e+00, 2.4392e-02, 9.4952e-01, 0.0000e+00],
[4.0854e-02, 7.2992e-01, 1.7494e-01, 0.0000e+00, 3.9046e-01, 0.0000e+00,
0.0000e+00, 1.1856e+00, 5.1254e-01, 1.4365e+00],
[0.0000e+00, 1.3372e+00, 0.0000e+00, 6.2340e-01, 0.0000e+00, 4.8263e-01,
3.6486e-01, 0.0000e+00, 1.4925e-01, 4.0236e-01],
[0.0000e+00, 0.0000e+00, 2.3011e-01, 2.8612e-01, 0.0000e+00, 2.9270e-01,
0.0000e+00, 0.0000e+00, 5.5580e-01, 0.0000e+00],
[1.1411e+00, 0.0000e+00, 5.2030e-01, 1.0582e+00, 5.4400e-04, 6.6906e-01,
0.0000e+00, 0.0000e+00, 0.0000e+00, 4.1712e-01],
[2.8783e-01, 0.0000e+00, 0.0000e+00, 0.0000e+00, 4.1535e-01, 0.0000e+00,
0.0000e+00, 3.2157e-01, 2.4875e-01, 0.0000e+00],
[8.6504e-01, 4.4471e-02, 5.2251e-01, 4.5288e-01, 0.0000e+00, 1.2464e+00,
0.0000e+00, 0.0000e+00, 0.0000e+00, 5.8638e-01],
[0.0000e+00, 7.3047e-01, 0.0000e+00, 0.0000e+00, 5.4288e-01, 9.1588e-01,
0.0000e+00, 6.0390e-01, 2.5176e-01, 4.7328e-01],
[0.0000e+00, 5.0342e-01, 1.2113e+00, 4.8887e-01, 0.0000e+00, 0.0000e+00,
-0.0000e+00, -0.0000e+00, -0.0000e+00, 6.7853e-02]],
grad_fn=<CompiledFunctionBackward>)
/opt/miniforge3/envs/nightly_conda_cuda116/lib/python3.8/site-packages/torch/_dynamo/eval_frame.py:366: UserWarning: TensorFloat32 tensor cores for float32 matrix multiplication available but not enabled.Consider setting `torch.set_float32_matmul_precision('high')`
warnings.warn(
eager: 1.265844482421875
compile: 4.382791015625
I’m not 100% sure, but would guess the Triton backend might need to use your locally installed CUDA toolkit, which might be older. Could this be the case?