Hi,
I created a detector with nn.ModuleList which contains many DNN networks each has 2 hidden layers and one output layers, and the forward function is as follows: each dnn in the nn.Modulelist takes the output of its previous dnn and gives new prediction which will be given to the next dnn in the nn.ModuleList, but when I checked training with params.grad, only the grads of the last dnn of the modulelist are being calculated but all of the rest are None, I don’t understand why backpropagation is not going through all the DNNs of the modulelist.
So basically on the params of the last DNN are being optimized.
Could you post a minimal and executable code snippet reproducing the issue?
The code is pretty long and have many details here are the main parts:
###############
def calculate_posteriors(self,sub_model,previous_prob,rx,H,i):
"""
Propagates the probabilities through the learnt networks.
Returns the probability matrix(users over columns) of symbols at iteration i
Prev_prob here is the Sym vector(sym_vec)
"""
next_probs_vec = (torch.zeros((H.shape[0],self.output,self.n_users))).to(self.device)
for user in range(self.n_users):
.................
if i==self.n_iter-1:
output = sub_model[user * self.n_iter + i](input.float())
else:
output = self.softmax1(sub_model[user * self.n_iter + i](input.float()))
next_probs_vec[:,:,user]=output
next_probs_vec=next_probs_vec.to(self.device)
return next_probs_vec
def forward(self,rx,H):
probs_vec= (torch.ones((H.shape[0],self.output,self.n_users))/self.output).to(self.device)
sym_vec=(torch.ones((H.shape[0],1,self.n_users),dtype=torch.complex64))
for i in range(self.n_iter):
'''
Encoding propagated probabilities and calculating interfering term which will give it to each dnn of each user
'''
####### Post-Processing
................
######################### Updating the predictions ###################################
#####The self.detector here is the module list
sym_vec=sym_vec.to(self.device)
probs_vec=self.calculate_posteriors(self.detector,sym_vec,rx,H,i)
return probs_vec
Then I just take the probs_vec from the forward which is the output of the last DNNs and calculate loss with cross-entropy which only updates these last DNNs but not the previous.
I hope this snippet of code gives a little idea about the context.
Just forgot to mention that here the sym_vec that I give it to the next DNNs is some kind of transformations I do it to the probs_vec(previous output), so before giving the prediction of the prev DNN to the next I encode it then give it to the next dnn for its calculations.
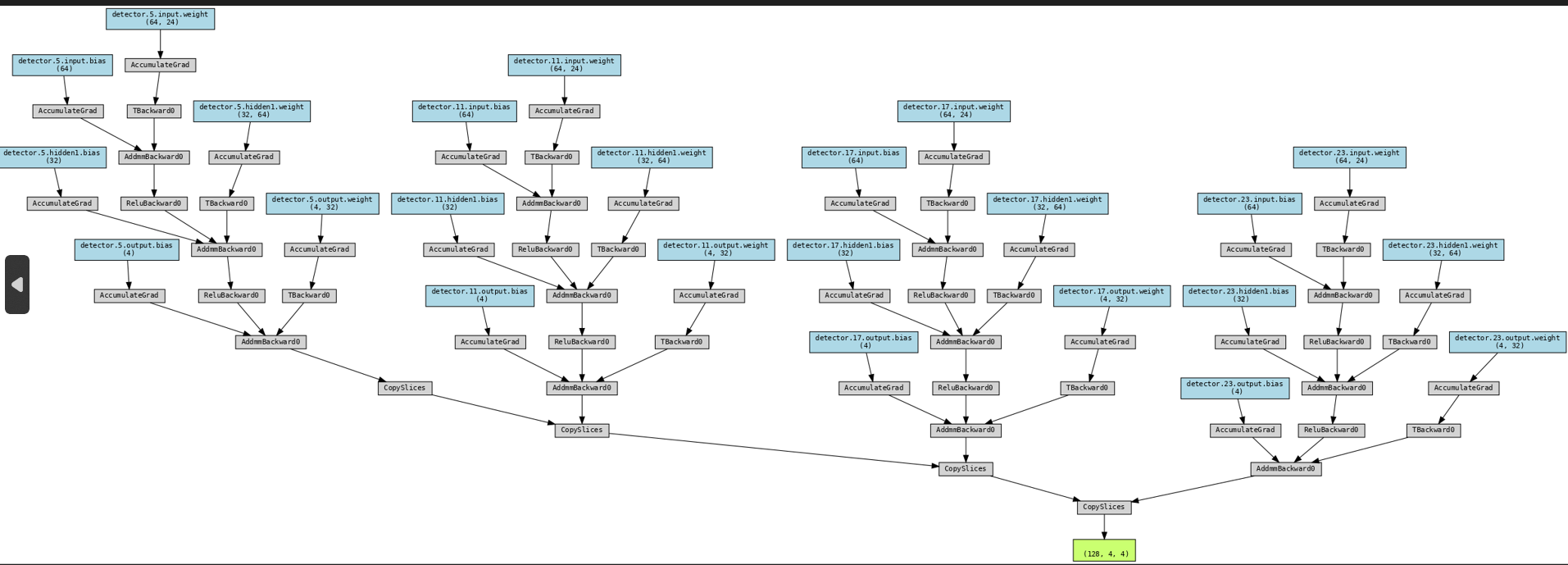
It’s unclear what exactly causes this behavior based on the provided code snippet. You could add debug print statements checking if input tensors from previous modules have a valid .grad_fn and if it disappears at one point to narrow down where the computation graph is cut.
I printed the grad_fn of all the inputs, that are being forwarded between the sub-models and it gives only none. Although the input.requires_grad is set to True.
I also checked the grad_fn of the outputs and they are not none, but I have to mention here that the input to the next dnn is not only the output of the previous dnn, I concatenate this output with another tensor then I give it to the next dnn.
Concatenating a tensor from a computation graph won’t break the graph as seen here:
x = torch.randn(1, requires_grad=True)
out = torch.cat((x, torch.randn(1)))
print(out.grad_fn)
# <CatBackward0 object at 0x7fcd2b3fbcd0>
out.mean().backward()
print(x.grad)
# tensor([0.5000])
so you might want to check why the .grad_fn of the inputs to the modules is set to None.
I think the problem is that I am not exactly using that prediction as input, I am encoding it in a new tensor then I concatenate that encoded tensor with other variable and give it as input, I don’t know how to include this new whole input (which includes the encoded version of the DNN output) in the computational graph. I thought just setting requires_grad=True will solve the issue.
No, creating a new tensor will detach it. Setting the .requires_grad attribute to True afterwards won’t reattach the tensor, so you would have to use torch.stack or torch.cat to concatenate tensors as seen in my example.
EDIT: also numpy arrays are not tracked by Autograd so the torch.from_numpy tensor also does not have a gradient history.
So this means that there is no way I can do an encoding to the previous output (Which is attached to the computational graph) and give it to the next DNN in a way that stays attached to the graph?
My previous code snippet shows that torch.cat works fine. A minimal and executable code snippet showing the exact operations detaching the graph would be helpful.
It should be here in the last line where I used the sym_vec tensor (encoded version of the output tensor) as input, which cannot be added to the graph in the first place after its creation
for iue in range(probs_vec.shape[2]):
for batch in range(H.shape[0]):
idx = torch.argmax(probs_vec[batch, :, iue]).item()
bb= OneHotDeco(self.Onehot[idx])
sym_vec[batch,:, iue] = torch.from_numpy(qam.encode(bb.astype(int)))
sym_vec=sym_vec.to(self.device)
sym_vec.requires_grad=True
probs_vec=self.calculate_posteriors(self.detector,sym_vec,rx,H,i)
It’s still unclear where sym_vec comes from. If it’s an output of a previous differentiable operation, the code will still work even though it’s treating the torch.from_numpy tensor as a constant:
w = torch.randn(2, requires_grad=True)
sym_vec = w * 2
print(sym_vec.grad_fn)
# <MulBackward0 object at 0x7fcd2b468100>
# replace with static tensor, which is not attached to a computation graph
sym_vec[1] = torch.from_numpy(np.random.randn(1))
print(sym_vec.grad_fn)
# <CopySlices object at 0x7fcd2b468550>
sym_vec.mean().backward()
print(w.grad)
# tensor([1., 0.])
If you replace all values of sym_vec, it will still work to call backward() on the tensor, but all gradients will be zero, since no gradient history is attached to the numpy arrays.
Actually sym_vec is a tensor that I initialized(torch.zeros) in the beginning of the forward function, so it contains the encoding values of probs_vec, then I give this sym_vec to the next dnn, it is initialized outside the loop of n_iter.
The thing here is that the encoding that I am doing is not a simple product or a sum I do it to a differentiable variable(prob_vec).
I think the only solution is to directly overwrite the values of prob_vec without initializing this new sym_vec, but still they don’t have same shape xD.