Hello everyone.
In studying Unsupervised-Classification , An incomprehensible logic was found.
Here is refer git-hub.
A function scan_train in train_utils.py
def scan_train(train_loader, model, criterion, optimizer, epoch, update_cluster_head_only=False):
"""
Train w/ SCAN-Loss
"""
total_losses = AverageMeter('Total Loss', ':.4e')
consistency_losses = AverageMeter('Consistency Loss', ':.4e')
entropy_losses = AverageMeter('Entropy', ':.4e')
progress = ProgressMeter(len(train_loader),
[total_losses, consistency_losses, entropy_losses],
prefix="Epoch: [{}]".format(epoch))
if update_cluster_head_only:
model.eval() # No need to update BN
else:
model.train() # Update BN
for i, batch in enumerate(train_loader):
# Forward pass
anchors = batch['anchor'].cuda(non_blocking=True)
neighbors = batch['neighbor'].cuda(non_blocking=True)
if update_cluster_head_only: # Only calculate gradient for backprop of linear layer
with torch.no_grad():
anchors_features = model(anchors, forward_pass='backbone')
neighbors_features = model(neighbors, forward_pass='backbone')
anchors_output = model(anchors_features, forward_pass='head')
neighbors_output = model(neighbors_features, forward_pass='head')
else: # Calculate gradient for backprop of complete network
anchors_output = model(anchors)
neighbors_output = model(neighbors)
# Loss for every head
total_loss, consistency_loss, entropy_loss = [], [], []
for anchors_output_subhead, neighbors_output_subhead in zip(anchors_output, neighbors_output):
total_loss_, consistency_loss_, entropy_loss_ = criterion(anchors_output_subhead,
neighbors_output_subhead)
total_loss.append(total_loss_)
consistency_loss.append(consistency_loss_)
entropy_loss.append(entropy_loss_)
# Register the mean loss and backprop the total loss to cover all subheads
total_losses.update(np.mean([v.item() for v in total_loss]))
consistency_losses.update(np.mean([v.item() for v in consistency_loss]))
entropy_losses.update(np.mean([v.item() for v in entropy_loss]))
total_loss = torch.sum(torch.stack(total_loss, dim=0))
optimizer.zero_grad()
total_loss.backward()
optimizer.step()
if i % 25 == 0:
progress.display(i)
A model is used to calculate two outputs
anchors_output = model(anchors)
neighbors_output = model(neighbors)
and two output is used to get a loss.
total_loss_, consistency_loss_, entropy_loss_ = criterion(anchors_output_subhead,
neighbors_output_subhead)
and back propagation
optimizer.zero_grad()
total_loss.backward()
optimizer.step()
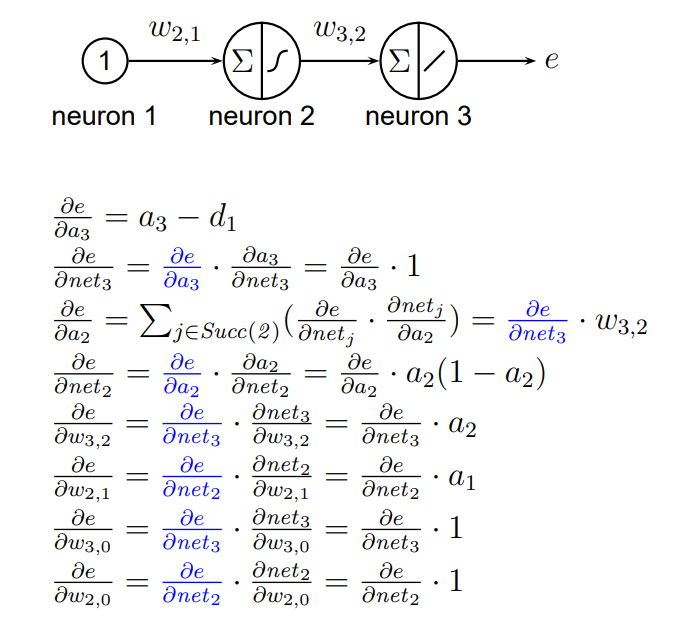
As far as I know, An output value of a node is need to backpropagate gradients through the node.
(e.g matmul gradient)
but in the upper case, the output value is not one.
Do I misunderstood the backpropagation?