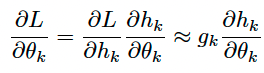I am trying to reproduce the results reported in Decoupled Neural Interfaces using Synthetic Gradients paper by PyTorch. The key idea in this paper is to approximate the gradient of the loss, using a synthetic gradient, gk, so that:
After calculating the gradient of the loss, I need to update the weights of the upstream layers. I am currently doing it this way:
output.backward(gradient_of_the_loss)
But I am not sure if this is correct and the documentation is not that helpful.
Yes, this will be correct, assuming that output is the h_k
and gradient_of_the_loss is the g_k in the expression
you posted.
(One quibble about your expression: The index k shouldn’t
be repeated in d h_k / d theta_k. I would have written d L / d theta_l ~ g_k d h_k / d theta_l, with an
implied sum over the index k)
The output is h_k, but by gradient_of_the_loss I meant the right hand side of the expression, i.e.: .
Because I think the backward method needs the gradient tensor as the option, which is built by multiplying synthetic gradient and the derivatives of activations w.r.t. weights.
With the exception of the duplicated index that I assume is a typo (see
my previous post), I think that the
in your original post is correct.
The way I read the image of the equation in your original post, L is the
scalar loss computed by applying a loss function to the predictions of your
model.
The theta_l are the “upstream” parameters of that model. (I use the
index l rather than k to fix the duplicated-index typo.)
The h_k are the output of your model, that is, its predictions.
d L / d h_k is the true gradient of the loss function with respect to the
predictions, while g_k is the “synthetic” gradient that approximates the
true gradient.
The equation you posted is just the (multi-dimensional) chain rule for
computing the gradient of L with respect to theta_l.
Assuming that by gradient_of_the_loss you mean either d L / d h_k
(where, again, the h_k are the predictions made by the model) or its
approximate, synthetic version, g_k, then whether you compute gradient_of_the_loss as the true or as the synthetic gradient and
whether you compute it using autograd or by some other means, the way
you get autograd to use the chain rule to complete the computation of d L / d theta_l is precisely by calling: