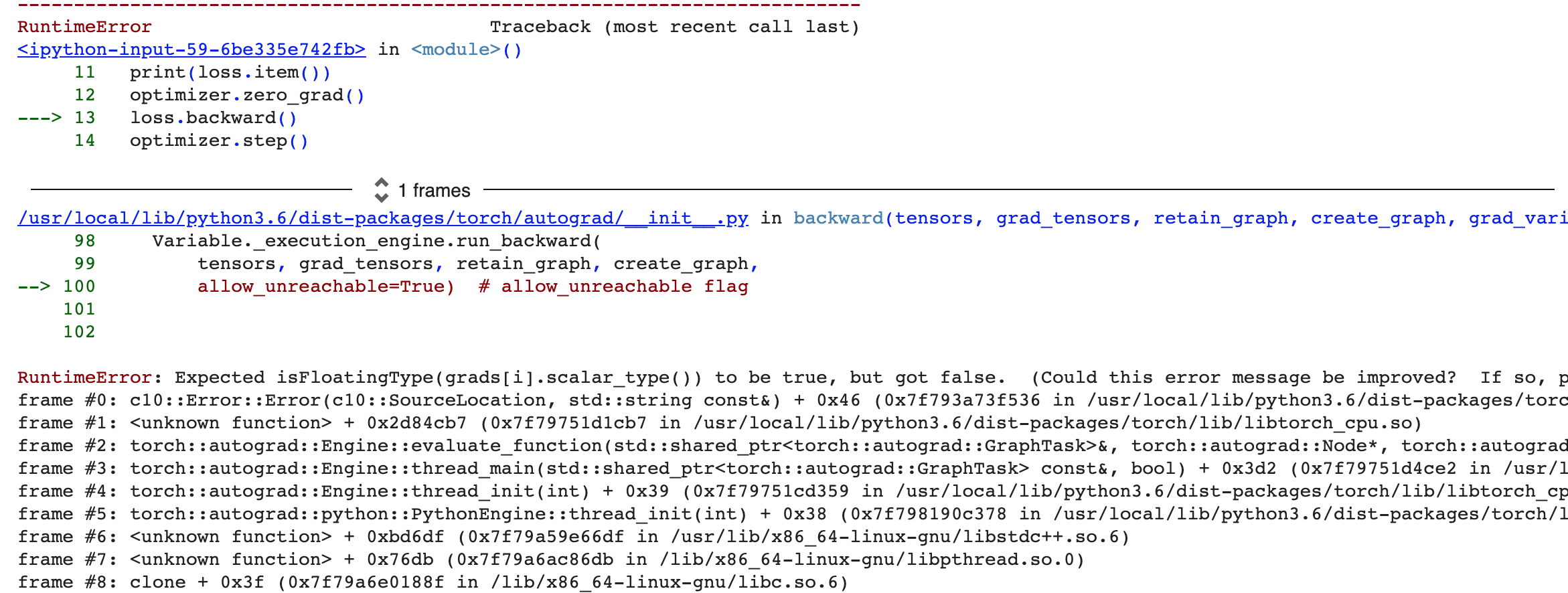
I’m trying to backprop through a long tensor but autograd complains. Changing it to float still throws an error.
Here’s a MWE, could some point out any alternative solutions?
x = torch.randn(100, 3)
y = torch.randint(3, (x.size(0),))
w = torch.nn.Parameter(torch.randn(3, 3))
optimizer = torch.optim.Adam([w])
for i in range(300):
pred = x @ w
y_hat = torch.softmax(pred, dim=1).argmax(dim=1)
mask = y_hat.eq(y).bitwise_not()
loss = F.cross_entropy(pred, y) + (y[mask].float() - y_hat[mask].float()).sum()
print(loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
Error Message: