env: use docker with ubuntu 20.04 system
Driver Version: 450.51.05
CUDA Version: 11.0
glibc 2.17
I tried to use DistributedDataParallel on single node with 2 GPUs, when start main process, the rank 0 process returned and finished, but rank1 still hang with GPU 1 100% and CPU 100%.
the model is causalnex and I tried to improve this model to GPU version.
model ref: GitHub - mckinsey/causalnex: A Python library that helps data scientists to infer causation rather than observing correlation.
my running code:
import numpy as np
import pandas as pd
import os
import causalnex
from causalnex.inference import InferenceEngine
from causalnex.network import BayesianNetwork
from causalnex.structure import StructureModel
from causalnex.structure.notears import from_pandas
from sklearn.datasets import load_diabetes
import torch
from sklearn.preprocessing import StandardScaler
from causalnex.structure import DAGRegressor
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import KFold
from sklearn.datasets import load_iris
from causalnex.structure import DAGClassifier
def main():
data = load_iris()
X, y = data.data, data.target
names = data["feature_names"]
os.environ['CUDA_LAUNCH_BLOCKING'] = '1'
sys.path.insert(0, "/home/casual_infer/causal_server/causalnex_dist_version")
clf = DAGClassifier(
alpha=0.1,
beta=0.9,
hidden_layer_units=[5],
fit_intercept=True,
standardize=True
)
X = pd.DataFrame(X, columns=names)
y = pd.Series(y, name="Flower_Class")
print('print clf.fit(X, y)')
clf.fit(X, y)
for i in range(clf.coef_.shape[0]):
print(f"MEAN EFFECT DIRECTIONAL CLASS {i}:")
print(pd.Series(clf.coef_[i, :], index=names).sort_values(ascending=False))
#clf.plot_dag(True)
if __name__ == '__main__':
main()
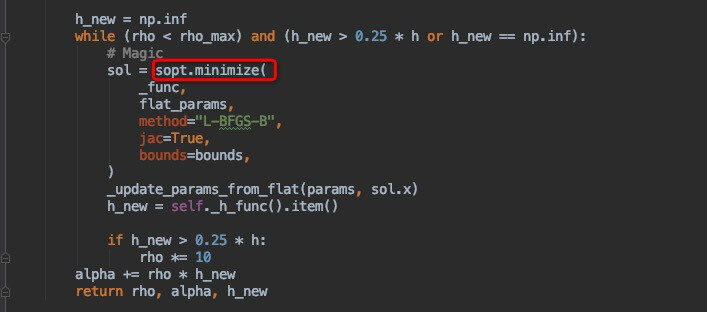
below is the source snippet code where it hang
running log:
Epoch [1/100], Step [1/5], h: 0.0495, gpu:1
Epoch [1/100], Step [1/5], h: 0.0421, gpu:0
Epoch [1/100], Step [2/5], h: 0.0078, gpu:0
Epoch [1/100], Step [2/5], h: 0.0052, gpu:1
Epoch [1/100], Step [3/5], h: 0.0008, gpu:0
return and finish gpu: 0
gdb py-bt result:
(gdb) py-bt
Traceback (most recent call first):
<built-in method run_backward of torch._C._EngineBase object at remote 0x7fb927d31c80>
File "/usr/local/lib/python3.8/dist-packages/torch/autograd/__init__.py", line 386, in backward
File "/usr/local/lib/python3.8/dist-packages/torch/tensor.py", line 477, in backward
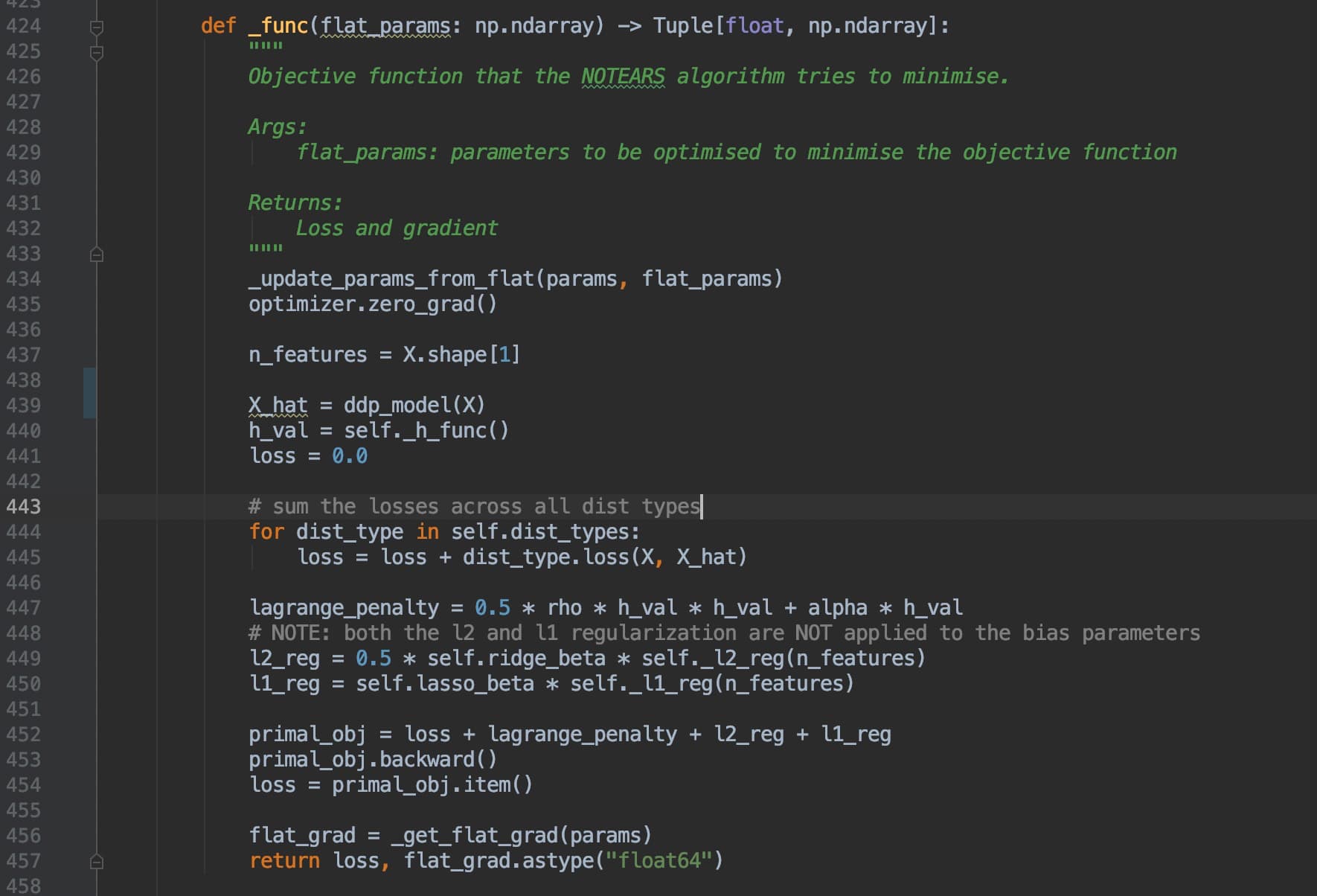
File "/home/casual_infer/causal_server/causalnex_dist_version/causalnex/structure/pytorch/core.py", line 453, in _func
primal_obj.backward()
File "/usr/local/lib/python3.8/dist-packages/scipy/optimize/optimize.py", line 68, in _compute_if_needed
fg = self.fun(x, *args)
File "/usr/local/lib/python3.8/dist-packages/scipy/optimize/optimize.py", line 74, in __call__
self._compute_if_needed(x, *args)
File "/usr/local/lib/python3.8/dist-packages/scipy/optimize/_differentiable_functions.py", line 130, in fun_wrapped
return fun(x, *args)
File "/usr/local/lib/python3.8/dist-packages/scipy/optimize/_differentiable_functions.py", line 133, in update_fun
self.f = fun_wrapped(self.x)
File "/usr/local/lib/python3.8/dist-packages/scipy/optimize/_differentiable_functions.py", line 226, in _update_fun
self._update_fun_impl()
File "/usr/local/lib/python3.8/dist-packages/scipy/optimize/_differentiable_functions.py", line 260, in fun_and_grad
self._update_fun()
File "/usr/local/lib/python3.8/dist-packages/scipy/optimize/lbfgsb.py", line 1128, in _minimize_lbfgsb
File "/usr/local/lib/python3.8/dist-packages/scipy/optimize/_minimize.py", line 5483, in minimize
File "/home/casual_infer/causal_server/causalnex_dist_version/causalnex/structure/pytorch/core.py", line 1236, in _dual_ascent_step
File "/home/casual_infer/causal_server/causalnex_dist_version/causalnex/structure/pytorch/core.py", line 801, in fit
File "/home/casual_infer/causal_server/causalnex_dist_version/causalnex/structure/pytorch/notears.py", line 1045, in dist_train_worker
File "/usr/local/lib/python3.8/dist-packages/torch/multiprocessing/spawn.py", line 19, in _wrap
fn(i, *args)
File "/usr/lib/python3.8/multiprocessing/process.py", line 108, in run
self._target(*self._args, **self._kwargs)
File "/usr/lib/python3.8/multiprocessing/process.py", line 571, in _bootstrap
File "/usr/lib/python3.8/multiprocessing/spawn.py", line 129, in _main
return self._bootstrap(parent_sentinel)
File "/usr/lib/python3.8/multiprocessing/spawn.py", line 628, in spawn_main
File "<string>", line 1, in <module>
**gdb bt result:**
gdb) bt
#0 futex_wait_cancelable (private=<optimized out>, expected=0, futex_word=0x60012388) at ../sysdeps/nptl/futex-internal.h:183
#1 __pthread_cond_wait_common (abstime=0x0, clockid=0, mutex=0x60012390, cond=0x60012360) at pthread_cond_wait.c:508
#2 __pthread_cond_wait (cond=0x60012360, mutex=0x60012390) at pthread_cond_wait.c:638
#3 0x00007fb92cbf2e30 in std::condition_variable::wait(std::unique_lock<std::mutex>&) () from /lib/x86_64-linux-gnu/libstdc++.so.6
#4 0x00007fb88b88d17b in torch::autograd::ReadyQueue::pop() () from /usr/local/lib/python3.8/dist-packages/torch/lib/libtorch_cpu.so
#5 0x00007fb88b8922c9 in torch::autograd::Engine::thread_main(std::shared_ptr<torch::autograd::GraphTask> const&) () from /usr/local/lib/python3.8/dist-packages/torch/lib/libtorch_cpu.so
#6 0x00007fb88b890310 in torch::autograd::Engine::execute_with_graph_task(std::shared_ptr<torch::autograd::GraphTask> const&, std::shared_ptr<torch::autograd::Node>) ()
from /usr/local/lib/python3.8/dist-packages/torch/lib/libtorch_cpu.so
#7 0x00007fb926795dcc in torch::autograd::python::PythonEngine::execute_with_graph_task(std::shared_ptr<torch::autograd::GraphTask> const&, std::shared_ptr<torch::autograd::Node>) ()
from /usr/local/lib/python3.8/dist-packages/torch/lib/libtorch_python.so
#8 0x00007fb88b88f36d in torch::autograd::Engine::execute(std::vector<torch::autograd::Edge, std::allocator<torch::autograd::Edge> > const&, std::vector<at::Tensor, std::allocator<at::Tensor> > const&, bool, bool, std::vector<torch::autograd::Edge, std::allocator<torch::autograd::Edge> > const&) () from /usr/local/lib/python3.8/dist-packages/torch/lib/libtorch_cpu.so
#9 0x00007fb926795bce in torch::autograd::python::PythonEngine::execute(std::vector<torch::autograd::Edge, std::allocator<torch::autograd::Edge> > const&, std::vector<at::Tensor, std::allocator<at::Tensor> > const&,bool, bool, std::vector<torch::autograd::Edge, std::allocator<torch::autograd::Edge> > const&) () from /usr/local/lib/python3.8/dist-packages/torch/lib/libtorch_python.so
#10 0x00007fb926796c9f in THPEngine_run_backward(THPEngine*, _object*, _object*) () from /usr/local/lib/python3.8/dist-packages/torch/lib/libtorch_python.so
#11 0x00000000005f5e79 in cfunction_call_varargs (kwargs=<optimized out>, args=<optimized out>, func=<built-in method run_backward of torch._C._EngineBase object at remote 0x7fb927d31c80>) at ../Objects/call.c:773
#12 PyCFunction_Call (func=<built-in method run_backward of torch._C._EngineBase object at remote 0x7fb927d31c80>, args=<optimized out>, kwargs=<optimized out>) at ../Objects/call.c:773
#13 0x00000000005f6a46 in _PyObject_MakeTpCall (callable=<built-in method run_backward of torch._C._EngineBase object at remote 0x7fb927d31c80>, args=<optimized out>, nargs=<optimized out>, keywords=<optimized out>)
at ../Include/internal/pycore_pyerrors.h:13
#14 0x0000000000570f1d in _PyObject_Vectorcall (kwnames=('allow_unreachable',), nargsf=<optimized out>, args=<optimized out>,
callable=<built-in method run_backward of torch._C._EngineBase object at remote 0x7fb927d31c80>) at ../Include/cpython/abstract.h:125
#15 _PyObject_Vectorcall (kwnames=('allow_unreachable',), nargsf=<optimized out>, args=<optimized out>, callable=<built-in method run_backward of torch._C._EngineBase object at remote 0x7fb927d31c80>)
at ../Include/cpython/abstract.h:115
#16 call_function (kwnames=('allow_unreachable',), oparg=<optimized out>, pp_stack=<synthetic pointer>, tstate=<optimized out>) at ../Python/ceval.c:4963
#17 _PyEval_EvalFrameDefault (f=<optimized out>, throwflag=<optimized out>) at ../Python/ceval.c:3515
#18 0x00000000005696da in PyEval_EvalFrameEx (throwflag=0, f=
Frame 0x7fb74933d610, for file /usr/local/lib/python3.8/dist-packages/torch/autograd/__init__.py, line 386, in backward (tensors=(<Tensor at remote 0x7fb749346040>,), grad_tensors=None, retain_graph=False, create_graph=False, grad_variables=None, grad_tensors_=(<Tensor at remote 0x7fb749346500>,))) at ../Python/ceval.c:741
#19 _PyEval_EvalCodeWithName (_co=<optimized out>, globals=<optimized out>, locals=<optimized out>, args=<optimized out>, argcount=<optimized out>, kwnames=<optimized out>, kwargs=0x7fb74ddeb210,
kwcount=<optimized out>, kwstep=1, defs=0x7fb9253c1788, defcount=4, kwdefs=0x0, closure=0x0, name='backward', qualname='backward') at ../Python/ceval.c:4298
#20 0x00000000005f6403 in _PyFunction_Vectorcall (func=<optimized out>, stack=0x7fb74ddeb1f0, nargsf=<optimized out>, kwnames=<optimized out>) at ../Objects/call.c:436
#21 0x00000000005703e6 in _PyObject_Vectorcall (kwnames=0x0, nargsf=<optimized out>, args=0x7fb74ddeb1f0, callable=<function at remote 0x7fb925343310>) at ../Include/cpython/abstract.h:127
#22 call_function (kwnames=0x0, oparg=<optimized out>, pp_stack=<synthetic pointer>, tstate=0x1782e90) at ../Python/ceval.c:4963
#23 _PyEval_EvalFrameDefault (f=<optimized out>, throwflag=<optimized out>) at ../Python/ceval.c:3469
#24 0x00000000005696da in PyEval_EvalFrameEx (throwflag=0,
f=Frame 0x7fb74ddeb040, for file /usr/local/lib/python3.8/dist-packages/torch/tensor.py, line 477, in backward (self=<Tensor at remote 0x7fb749346040>, gradient=None, retain_graph=None, create_graph=False, relevant_args=(<...>,), has_torch_function=<function at remote 0x7fb92531b160>, handle_torch_function=<function at remote 0x7fb92531b0d0>)) at ../Python/ceval.c:741
#25 _PyEval_EvalCodeWithName (_co=<optimized out>, globals=<optimized out>, locals=<optimized out>, args=<optimized out>, argcount=<optimized out>, kwnames=<optimized out>, kwargs=0x4bb58948,
kwcount=<optimized out>, kwstep=1, defs=0x7fb92559a758, defcount=3, kwdefs=0x0, closure=0x0, name='backward', qualname='Tensor.backward') at ../Python/ceval.c:4298
#26 0x00000000005f6403 in _PyFunction_Vectorcall (func=<optimized out>, stack=0x4bb58940, nargsf=<optimized out>, kwnames=<optimized out>) at ../Objects/call.c:436
#27 0x000000000056b5e0 in _PyObject_Vectorcall (kwnames=0x0, nargsf=<optimized out>, args=0x4bb58940, callable=<function at remote 0x7fb9255a95e0>) at ../Include/cpython/abstract.h:127
#28 call_function (kwnames=0x0, oparg=<optimized out>, pp_stack=<synthetic pointer>, tstate=0x1782e90) at ../Python/ceval.c:4963
#29 _PyEval_EvalFrameDefault (f=<optimized out>, throwflag=<optimized out>) at ../Python/ceval.c:3486
#30 0x00000000005696da in PyEval_EvalFrameEx (throwflag=0,
f=Frame 0x4bb58730, for file /home/casual_infer/causal_server/causalnex_dist_version/causalnex/structure/pytorch/core.py, line 453, in _func (flat_params=<numpy.ndarray at remote 0x7fb74a5b8750>, n_features=7, X_--Type <RET> for more, q to quit, c to continue without paging--
I have tried a lot and can’t find out the main reason.