Hi everyone !
I’m currently learning on how to use torchscript (and PyTorch in general), I have done a benchmark (CPU & GPU) on differents models : gru (native PyTorch implementation), lstm (native PyTorch implementation), custom model implementation (that we will call custom_model) and jit.script(custom_model).
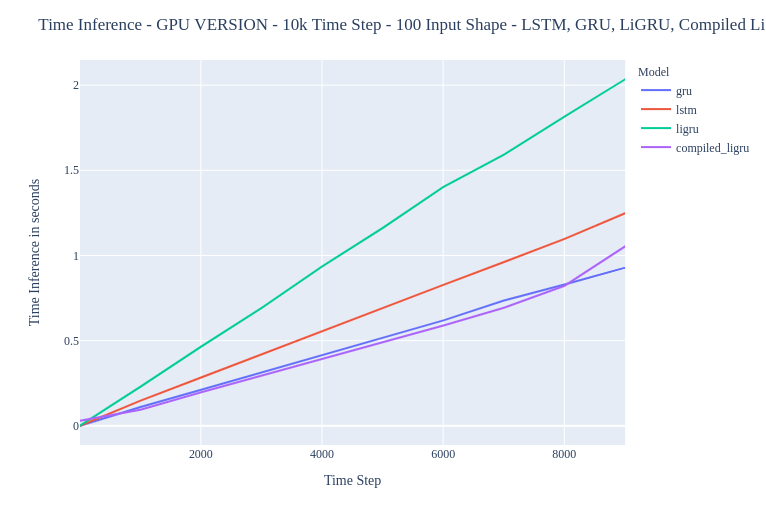
In inference I have seen that my custom model was very very slow (it’s a sort of custom GRU so that’s “normal” that he is very slow because of the loop on time step) and with the jit.script implementation my very very slow model was very good ! He reached the cudaNN implementation.
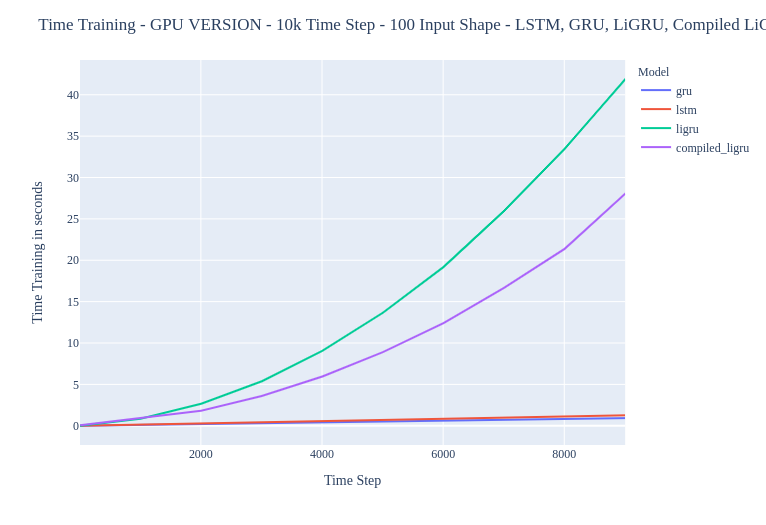
But I was wondering something, in training he was better than my custom implementation but very slow in comparison to the gru/lstm cudaNN implementation.
So my question is the following : what is in torchscript that is not doing “good” in optimizing the backward pass ?
I have read a lot’s about this subject and the “answer” that I have found is that broadcasting is complicating the job of AD. But I haven’t fully understand well why. I see improvment so there is optimization that is doing good but not fully that would lead to the same perf as cudaNN implementation.
My second question is : do numba or other framework could help to reach performances of cudaNN implementation ? In my case it’s the for loop on time step (seq_len) that is generating this slower results
custom_model = ligru
jit.script(custom_model) = torch.jit.script(ligru)
Results are the following :
Training results :
Thanks you a lot !
Take care of you guys.
The ressources that I have used (and others but I’m limited with links):