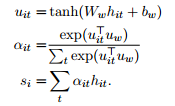I am trying to implement a batch matrix multiplication like the first equation in this image.
The weight and bias are defined as a parameter in the model. I am making a copy of the bias term to the entire batch.
def batch_matmul_bias(seq, weight, bias, nonlinearity=''):
s = None
bias_dim = bias.size()
for i in range(seq.size(0)):
_s = torch.mm(seq[i], weight)
_s_bias = _s + bias.expand(bias_dim[0], _s.size()[0])
print _s_bias.size()
if(nonlinearity=='tanh'):
_s_bias = torch.tanh(_s_bias)
_s_bias = _s_bias.unsqueeze(0)
if(s is None):
s = _s_bias
else:
s = torch.cat((s,_s_bias),0)
return s.squeeze()
The forward pass works, but when doing the backward pass, I am getting a size mismatch error.
RuntimeError: sizes do not match at /data/users/soumith/miniconda2/conda-bld/pytorch-cuda80-0.1.7_1485448159614/work/torch/lib/THC/generated/../generic/THCTensorMathPointwise.cu:216
Hi,
Is there any reason why you do not use builtin functions?
I guess you could do something along the lines of:
import torch.nn.functional as F
def batch_matmul_bias(seq, weight, bias, nonlinearity=''):
s = F.linear(seq, weight, bias)
if nonlinearity=='tanh':
s = F.tanh(s)
return s
Be careful because these functions supports only batch mode.
So if your input is not a batch, don’t forget to use .unsqueze(0) to make it as a batch of 1 element.
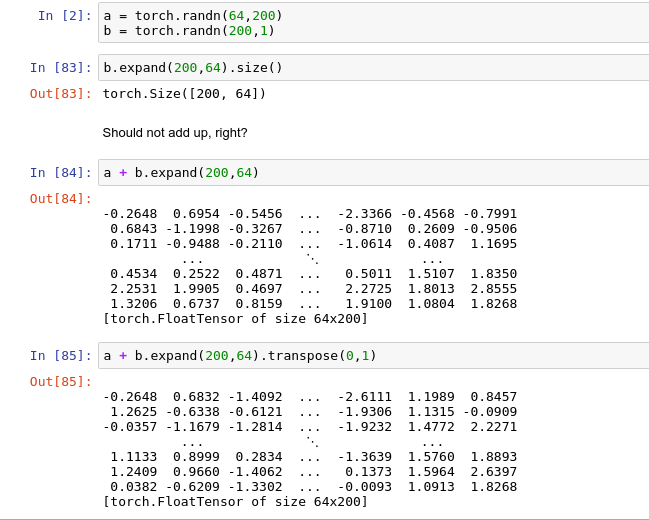
I managed to fix it. For future reference, I was sloppy and did not properly reshape the bias term. Doing a transpose of the bias term is the one I forgot.
@Sandeep42 it’s a bug that has been fixed 2 days ago (gradient’s weren’t viewed properly). The problem is that the basic ops like +, *, - and / don’t care about the sizes of the inputs, but only that their number of elements match. The result has always the size of the first operand - this explains your screenshot.
I think we should add some strict size checking there anyway (once we add broadcasting)