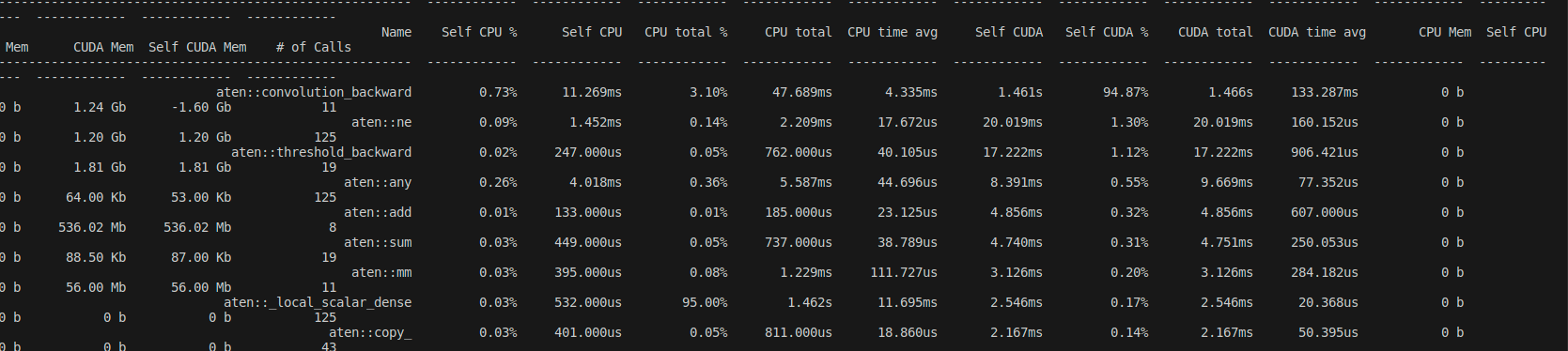
When I am training a simple resnet which involves convolutional network forward and backward on celebA dataset, I find out that the loss.backward() (MSE loss) whose time consumption increases linearly with batch_size. A simple profile is as follows:

- Here is a part of backward profiling. The batch_size is set to 128, and GPU consumption is about 1.5GB/12GB.